Anti-Patterns in der Microservice-Entwicklung: Häufige Probleme und wie man sie vermeidet
Microservices sind eine sehr robuste und leistungsfähige Architekturwahl, und zahlreiche namhafte Softwareunternehmen wählen dieses modernes Konzept in der Entwiklung. Dennoch treten viele Fehler oft auf, die Leistung, Skalierbarkeit und Kosten negativ beeinflussen können. In diesem Artikel gehen wir auf diese Fehler näher ein. Wir erklären auch, wie man die Fehler am effektivsten vermeidet. Bleiben Sie dran und erfahren Sie mehr darüber, wie Sie diese Probleme schnell und einfach umgehen können.
Was sind Microservice Anti-Patterns?
Im Kontext der Softwareentwicklung sind Anti-Patterns technische Entscheidungen im Entwicklungsprozess, die zunächst vorteilhaft und effizient erscheinen, jedoch später Probleme auslösen. Solche Implementierungen verstoßen meist gegen die Kernprinzipien der Microservices Software Architektur, wie lose Kopplung, unabhängige Bereitstellung und Skalierbarkeit. Das führt zu technischem Schuldenaufbau, operativen Engpässen und Instabilitäten.
Diese Anti-Patterns entstehen häufig, weil sie auf den ersten Blick einfach und schnell umsetzbar sind. Sie kopieren Muster aus monolithischen Systemen, ohne sie richtig anzupassen. Außerdem wird die Komplexität verteilter Systeme oft unterschätzt. Diese architektonischen Fehler können dazu führen, dass die Leistung der Microservices beeinträchtigt wird, die Wartung teurer und schwieriger wird und damit der eigentliche Nutzen dieses Architekturkonzepts verloren geht. Besser erklärt: Microservices sind ein Softwarearchitekturstil, der eine Anwendung in viele kleine, unabhängige Dienste aufteilt, die verschiedene Zwecke haben. Dazu gehören:
- Flexibilität: Die Aktualisierung eines Dienstes sollte keinen anderen beeinträchtigen, wodurch jeder Dienst flexibler wird. So können zum Beispiel „Haupt“-Dienste die wichtigsten Teile eines Projekts beherbergen, während „Satelliten“-Dienste genutzt werden, um neue Ideen zu testen, zu entwickeln und das Geschäft zu skalieren.
- Skalierbarkeit: Da jeder Dienst unterschiedliche Funktionen hat, ist es einfacher, die meistgenutzten Dienste zu skalieren. Die weniger wichtigen Dienste bleiben unverändert, was erhebliche Kosten im Cloud-Betrieb spart.
- Geschwindigkeit: Eine klare Struktur erleichtert und beschleunigt die Entwicklung neuer Funktionen und deren Bereitstellung. Das ist entscheidend, um den Wettbewerb zu gewinnen und das Geschäft zu erweitern. Heutzutage wird das Unternehmen, das sich am besten an neue Standards anpasst und schneller Innovationen liefert, gegenüber der Konkurrenz erfolgreich sein.
Wie erkennt man Anti-Patterns im Unternehmen?
Microservices bieten zwar schnellere Innovation, bessere Skalierbarkeit und höhere Ausfallsicherheit, doch das ist nicht immer gewährleistet. Wenn Ihr Code mit Anti-Patterns „infiziert“ ist, wird das gesamte Unternehmen betroffen – die Entwicklung wird langsamer und unübersichtlicher, Bugs treten häufiger auf, und die Wartungskosten steigen. Hier finden Sie einige typische Merkmale der Anti-Patterns:
- Steigende Betriebskosten: Jedes implementierte Anti-Pattern erhöht die versteckte Komplexität. Die Anzahl der Dienste und Integrationen nimmt zu und der Infrastrukturaufwand steigt, was Ihre Ressourcen erheblich belastet und die Gewinnspanne verringert.
- Verlangsamte Agilität: Starke Kopplung zwischen Diensten oder schlecht gestaltete Abhängigkeiten erschweren die Bereitstellung neuer Funktionen, verlangsamen Entwicklungszyklen und stehen den Innovationen im Weg, da Entwickler oft mit Problemen konfrontiert sind.
- Nachlassende Qualität und Zuverlässigkeit: Instabile Systeme reagieren bereits auf kleine Änderungen mit Systemausfällen, was zu längeren Stillstandszeiten, unzufriedenen Nutzern und Umsatzverlusten führt.
- Frustriertes Personal und Mitarbeiterfluktuation: Entwickler pflegen ungern überkomplizierte, instabile Systeme. Die hohe technische Schuld führt zu Burnout und erschwert die Gewinnung und Bindung qualifizierter Fachkräfte.
Aus kommerzieller Sicht multipliziert jedes Microservice-Anti-Pattern die Ausgaben, verlangsamt Innovationen und gefährdet Ihren Ruf. Die Qualität Ihres Produkts hängt vom Code ab. Ist dieser schlecht, führt das zu Kundenunzufriedenheit und Abwanderung, was negativ Ihr Geschäft und die Leistungskennzahlen bewirkt.
Häufige Anti-Patterns in der Microservice-Entwicklung
Nun gehen wir tiefer darauf ein, was genau diese Anti-Patterns sind und welche tatsächlichen Auswirkungen sie mitbringen.
Der verteilte Monolith
Eines der häufigsten Probleme bei der Erstellung von Microservices entsteht, wenn die Software Architektur vor der Entwicklungsphase nicht sorgfältig geplant wird. Dadurch entsteht ein „versteckter Monolith“: die Dienste sind weiterhin eng miteinander gekoppelt und haben starke Abhängigkeiten, sie sind also nicht wirklich „mikro“. Daraus resultieren verschiedene Probleme wie unterbrochene Deployment-Pipelines, verringerte Testgenauigkeit und eine überteuerte sowie komplexe Skalierbarkeit. All das verringert massiv die Zuverlässigkeit des Systems. Dieses Problem macht den Code schwer zu warten, zu verstehen und zu debuggen. So wird die Arbeit der Entwickler ebenfalls erschwert, was den Entwicklungsprozess verlangsamt.
Überengineering der Architektur
Ebenso problematisch ist das entgegengesetzte Extrem zum vorherigen Problem: Es ist sowohl schlecht, einen lose verteilten Monolithen zu haben, als auch diese Architektur zu überengineeren und unnötige Microservices zu schaffen. Dies führt zu erhöhter Komplexität, erschwert die Nachverfolgung der Funktionalität jedes Dienstes und steigert zudem die Cloud-Kosten, da viele verschiedene Systeme gleichzeitig betrieben werden müssen.
Gemeinsame Datenbank zwischen Diensten
Die Erstellung einer gemeinsamen Datenbank zur Verbindung verschiedener Microservices ist oft unvernünftig. Das widerspricht grundsätzlich den Kernprinzipien dieser Architektur und macht den Betrieb fragiler und unzuverlässiger. Es verletzt das Prinzip der Unabhängigkeit der Microservices, da alle ihre Daten aus derselben Datenbank beziehen. Falls mit dieser Datenbank etwas passiert, sind alle Dienste gleichzeitig davon betroffen. Im Endeffekt funktioniert das System dann eher wie ein Monolith, wodurch der eigentliche Zweck der Einführung von Microservices vollständig infrage gestellt wird.
Überflüssige Kommunikation und viele Netzwerkaufrufe
Microservices sind zwar eigenständige Systeme, müssen aber trotzdem miteinander vernetzt sein. Dafür verwenden sie Netzwerkaufrufe, um Nachrichten zu senden und andere Dienste zu steuern, zum Beispiel über Simple Queue Service (SQS) von AWS oder vergleichbare Systeme. Wenn zu viele Nachrichten zwischen den Diensten ausgetauscht werden, kann das zu Verzögerungen und Engpässen führen. Dadurch werden die Prozesse langsamer und die Nutzer sind oft unzufrieden. Das deutet meist darauf hin, dass die Kommunikation nicht gut geplant ist und unnötige Daten zwischen den Diensten ausgetauscht werden. Aus diesem Grund ist eine umfassende Prüfung und Anpassung erforderlich.
Unterschätzung der Sicherheitsanforderungen bei der dienstübergreifenden Kommunikation
Die Vernachlässigung der Sicherheit kann die Nutzer der Software in Gefahr stellen, da es die Sicherheit der Anwendung kompromittiert. Dieses Problem entsteht, wenn der Kommunikationsverkehr zwischen den Diensten nicht authentifiziert oder verschlüsselt wird. Durch diese Schwachstelle können Angreifer Nachrichten abfangen, den Dienst übernehmen, sensible Daten stehlen oder Kundendaten manipulieren. Es ist daher ausschlaggebend, dass diese Kommunikation so sicher und verschlüsselt wie möglich gestaltet wird, da sehr sensible Informationen übertragen werden und somit die Datenbank geschützt werden muss.
Architektur-Übersicht: Abgegrenzte Kontexte und Dienstleistungsverträge
Das nachfolgende Beispiel zeigt anschaulich, welchen Unterschied es macht, wenn Design-Pattern bei der Entwicklung von Microservices korrekt angewendet werden. Das System funktioniert besser, und jeder Service hat eine klare, gut strukturierte Rolle.
Abgegrenzte Kontexte (Domain-Driven Design) & Zuständigkeiten
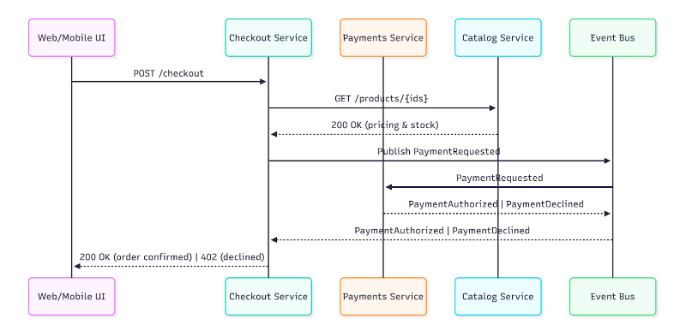
Dieses Diagramm zeigt, wie jeder Service einem klaren, spezifischen Domänenkontext zugeordnet sein muss (zum Beispiel: Checkout, Katalog, Zahlungen, Kunde). Jeder Kontext hat seine eigene Logik und Datenbank; die Kommunikation zwischen den Services erfolgt über explizite Verträge (wie REST-APIs oder Events). Alles ist gut organisiert und klar abgegrenzt. Dadurch wird das Anti-Pattern einer gemeinsamen Datenbank vermieden und die Autonomie der einzelnen Services gefördert.
Eventgesteuerter Checkout-Prozess (Anti-chatty, ausfallsicher)
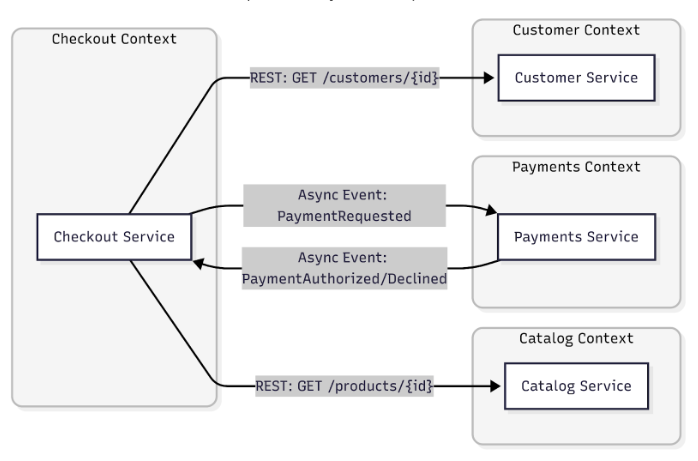
Dieses Sequenzdiagramm zeigt einen ereignisgesteuerten Checkout-Prozess, bei dem der Checkout-Service den Kauf orchestriert, jedoch Aufgaben an andere Services delegiert werden.
- Der Kunde macht eine Bestellung im Checkout-Service.
- Der Katalog-Service liefert Informationen zum Produkt und Lagerbestand.
- Der Checkout veröffentlicht das Ereignis PaymentRequested auf dem System-Message-Bus.
- Der Zahlungsservice verarbeitet die Zahlung und sendet die Antwort als Ereignis zurück (PaymentAuthorized oder PaymentDeclined).
- Der Checkout empfängt dieses Ereignis und sendet eine Antwort an den Kunden.
Dieses Muster vermeidet das Chatter-Problem, indem es übermäßige synchrone Aufrufe zwischen Services verhindert, und fördert gleichzeitig die Resilienz. Falls der Zahlungsservice für einige Sekunden ausfällt, kann das System automatisch wiederhergestellt werden, sobald der Service wieder verfügbar ist.
Wie man Anti-Patterns der Microservices vermeidet
Um Anti-Patterns zu verhindern, ist es wichtig, von Beginn an einen organisierten Architekturansatz zu etablieren und sicherzustellen, dass das gesamte Team dieses Konzept genau befolgt. Ein Schlüssel dazu ist die Einführung bewährter Methoden, die Dienste unabhängig, wartbar und resilient halten.
Einige der wichtigsten Strategien sind:
- Domain-Driven Design (DDD): Orientieren Sie die Dienste an fachlichen Kontexten, nicht an technischen Schichten. Das reduziert Kopplungen und stellt sicher, dass jeder Dienst einen klaren Kontext mit eigener Logik und Daten hat.
- Asynchrone Kommunikation: Verwenden Sie, wo möglich, Nachrichtenwarteschlangen oder ereignisgesteuerte Architekturen statt direkter, synchroner Aufrufe. Das reduziert Latenzen und verhindert Ausfallsketten bei Problemen einzelner Dienste.
- Regelmäßiges Prüfen und Refaktorierung: Planen Sie regelmäßige Reviews ein, um Anti-Patterns frühzeitig zu erkennen und zu beheben, bevor sie finanziell belastend werden.
- Investition in Observability: Mit zentralisiertem Logging, verteiltem Tracing und Metriken können Fehler schnell genau lokalisiert werden. Dies ist entscheidend für die schnelle Diagnose und Vermeidung größerer Probleme.
- Modell nach Domänen: abgegrenzte Kontexte und Aggregate: Vermeiden Sie gemeinsame „globale Entitäten“. Jeder Kontext besitzt seine eigene Persistenzschicht. Dadurch kann jeder Service unabhängig weiterentwickelt werden, ohne die anderen zu beeinträchtigen. Hier ein Beispiel mit Prisma-Modellen:
// apps/catalog/prisma/schema.prisma
model Product {
id String @id @default(cuid())
sku String @unique
name String
priceCents Int
stockQty Int
updatedAt DateTime @updatedAt
}
// apps/checkout/prisma/schema.prisma
model Order {
id String @id @default(cuid())
customerId String
totalCents Int
status OrderStatus @default(PENDING)
createdAt DateTime @default(now())
}
enum OrderStatus {
PENDING
PAID
DECLINED
}
Damit hat jeder Service eigene Modelle und kann unabhängig weiterentwickelt werden, ohne Anpassungen in anderen Services zu erfordern.
- Priorisieren Sie Async: Ereignisse statt synchroner Aufrufe. Das reduziert unnötigen Nachrichtenverkehr (Chatter) und Aggregationslatenzen, verbessert die Ausfallsicherheit während Netzwerkunterbrechungen und fördert insgesamt einen reibungslosen Betrieb der Software.
Veröffentliche das Ereignis „PaymentRequested“ (Kafka/SQS-neutral) mit TypeScript:
// checkout/src/paymentPublisher.ts
type PaymentRequested = {
event: "PaymentRequested";
version: 1;
data: { orderId: string; totalCents: number; customerId: string };
};
export async function publishPaymentRequested(
bus: { publish: (topic: string, msg: unknown) => Promise },
payload: PaymentRequested["data"]
) {
const message: PaymentRequested = {
event: "PaymentRequested",
version: 1,
data: payload,
};
await bus.publish("payments", message); // Kafka topic / SQS queue
}
Zahlungsdienst-Verbraucher mit Python:
# payments/consumer.py
from typing import TypedDict
class PaymentRequested(TypedDict):
event: str
version: int
data: dict
def handle_payment_requested(msg: PaymentRequested, gateway):
order_id = msg["data"]["orderId"]
amount = msg["data"]["totalCents"]
approved = gateway.authorize(amount)
event = {
"event": "PaymentAuthorized" if approved else "PaymentDeclined",
"version": 1,
"data": {"orderId": order_id}
}
bus.publish("checkout", event)
- Designen Sie klare, versionierte APIs (REST + OpenAPI): Durch die Gestaltung versionierter Verträge können Sie unabhängige Deployments durchführen, was weniger Abstimmung zwischen den Teams erfordert und schnellere Entwicklungszyklen ermöglicht. Hier ist ein Beispiel für einen Vertrag, der mit OpenAPI für unseren Zahlungsservice erstellt wurde.
openapi: 3.0.3
info:
title: Payments API
version: 1.0.0
paths:
/v1/payments/authorize:
post:
summary: Authorize a payment
requestBody:
required: true
content:
application/json:
schema:
type: object
required: [orderId, totalCents]
properties:
orderId: { type: string }
totalCents: { type: integer, minimum: 1 }
responses:
'200':
description: Authorization result
content:
application/json:
schema:
type: object
properties:
authorized: { type: boolean }
authId: { type: string, nullable: true }
- End-to-End-Observability (Logs, Metriken, Tracing): Sie kann zu schnelleren Diagnosen führen, Daten für SLO/SLI fördern und zu einer niedrigeren MTTR beitragen. Außerdem macht sie Ihre Anwendung leichter zu debuggen und zu verstehen.
// payments/src/otel.ts
import { NodeSDK } from "@opentelemetry/sdk-node";
import { getNodeAutoInstrumentations } from "@opentelemetry/auto-instrumentations-node";
import { OTLPTraceExporter } from "@opentelemetry/exporter-trace-otlp-http";
export const sdk = new NodeSDK({
traceExporter: new OTLPTraceExporter({ url: process.env.OTLP_URL }),
instrumentations: [getNodeAutoInstrumentations()],
});
// index.ts
import { sdk } from "./otel";
sdk.start().then(() => {
// start HTTP server / consumer here
});
Strukturierte Logs:
// payments/src/logger.ts
export const log = (level: "info"|"warn"|"error", msg: string, ctx: Record<string, unknown> = {}) =>
console.log(JSON.stringify({ level, msg, ts: new Date().toISOString(), ...ctx }));
- Standardmäßige Resilienz: Implementieren Sie Circuit Breaker, Wiederholungen und Timeouts, um Kaskadenausfälle zu vermeiden und eine sanfte Degradierung zu gewährleisten. Hier ist ein Beispiel mit Spring Boot und Resilience4j:
// catalog-client/src/main/java/com/acme/catalog/CatalogClient.java
@FeignClient(name = "catalog", url = "${catalog.url}")
public interface CatalogClient {
@GetMapping("/v1/products/{id}")
ProductDto getProduct(@PathVariable String id);
}
// checkout/src/main/java/com/acme/checkout/ProductGateway.java
@Service
public class ProductGateway {
private final CatalogClient catalog;
public ProductGateway(CatalogClient catalog) { this.catalog = catalog; }
@CircuitBreaker(name = "catalog", fallbackMethod = "fallback")
@Retry(name = "catalog")
@TimeLimiter(name = "catalog")
public CompletableFuture get(String id) {
return CompletableFuture.supplyAsync(() -> catalog.getProduct(id));
}
- Vertragstests: Sie vermeiden unsichtbare Verflechtungen zwischen Services. Mit diesem Muster wird Ihre CI-Pipeline Sie vor dem Deployment warnen, falls der Anbieter den Vertrag bricht. Hier ist ein Beispiel mit PactJS:
// checkout/test/payments.pact.test.js
const { Pact } = require("@pact-foundation/pact");
const { like, integer, boolean } = require("@pact-foundation/pact").Matchers;
const fetch = require("node-fetch");
describe("Payments contract", () => {
const provider = new Pact({ consumer: "Checkout", provider: "Payments" });
beforeAll(() => provider.setup());
afterAll(() => provider.finalize());
test("authorize payment", async () => {
await provider.addInteraction({
state: "payment can be authorized",
uponReceiving: "a request to authorize",
withRequest: {
method: "POST",
path: "/v1/payments/authorize",
body: { orderId: like("ord_123"), totalCents: integer(1000) },
headers: { "Content-Type": "application/json" }
},
willRespondWith: {
status: 200,
headers: { "Content-Type": "application/json" },
body: { authorized: boolean(true), authId: like("auth_abc") }
}
});
const res = await fetch(provider.mockService.baseUrl + "/v1/payments/authorize", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ orderId: "ord_123", totalCents: 1000 })
});
expect(res.status).toBe(200);
});
});
Durch die Integration dieser Praktiken in Ihre Entwicklungskultur schützen Sie Ihre Microservices Entwicklung, senken die Wartungskosten, beschleunigen die Bereitstellung und bauen ein System auf, das sich Ihren Geschäftszielen anpasst. So profitieren Sie von der Leistungsfähigkeit dieser Architektur, die Ihr System zukunftsfähig und wettbewerbsfähig macht.
Implementierungscheckliste für ein gesundes System
- ✅ Domänenkontexte und Banken nach Diensten getrennt (keine gemeinsamen Datenbanken);
- ✅Versionierte APIs + Vertragstests im CI;
- ✅ Asynchrone Ereignisse für kritischere Integrationen zwischen Diensten;
- ✅ Belastbarkeit: Timeout, Wiederholung, Leistungsschalter, Fallback;
- ✅ Observability: strukturierte Protokolle, Metriken, Ablaufverfolgung;
- ✅ Sicherheit: mTLS/JWT zwischen Diensten, verwaltete Geheimnisse.
Durch Befolgen dieser Schritte können Sie die Betriebskosten senken, Releases beschleunigen und Vorfälle minimieren, wodurch Ihr Produkt zuverlässiger und ausfallsicherer wird.
Der ROI gesunder Microservice-Praktiken
Gute Microservice-Architektur bedeutet nicht nur sauberen Code – sie ist eine strategische Investition, die messbare Geschäftsergebnisse liefert. Wenn Sie gesunde Microservice-Praktiken befolgen, erzielen Sie sowohl technische Exzellenz als auch wirtschaftliche Vorteile, steigern das Tempo, überholen sehr bald Ihre Konkurrenten und erobern einen größeren Marktanteil.
Dadurch profitieren Sie ebenfalls von schnelleren Markteinführungszeiten, verbesserter Skalierbarkeit, tieferen Kosten bei Vorfällen und optimiertem Ressourcenverbrauch. Das Ergebnis ist ein gut durchdachtes und professionell umgesetztes Projekt, das einfach funktioniert und von Ihren Kunden gern genutzt wird, was zu höherer Zufriedenheit und Kundenbindung führt und sich direkt auf Ihre KPIs auswirkt.
Gesunde Microservice-Praktiken sind sehr rentabel. Die Investition in disziplinierte Architektur und Prozesse zahlt sich durch geringere Betriebskosten, erhöhte Agilität und eine stärkere Marktposition aus. Falls Sie Unterstützung bei der gesunden Implementierung von Microservices in Ihre Prozesse brauchen, können Sie Beratungsunternehmen wie Chudovo kontaktieren – klicken Sie hier, um uns Ihre Anforderungen mitzuteilen und ein unverbindliches Angebot für Ihr Projekt zu erhalten!
Fazit
Abschließend lässt sich sagen, dass Microservices keine magische Lösung oder Allheilmittel für die Herausforderungen Ihres Projekts sind. Wenn die Architektur, der Aufbau und der Code unprofessionell sind, entstehen immer mehr Probleme – das System wird immer komplexer zu warten, Ihre Cloud-Kosten steigen schnell, die Probleme breiten sich aus und schädigen das Nutzererlebnis.
Es ist daher super wichtig, Anti-Patterns im System zu vermeiden, insbesondere für die Grundlage Ihres Produkts. Zu den häufigsten Anti-Patterns gehören gemeinsame Datenbanken zwischen Services, Services mit übermäßigen Netzwerkaufrufen und der Aufbau verteilter Monolithen. Alle basieren mehr oder weniger auf denselben Fehlern: zu wenig Achtsamkeit für Architektur und Integrität von Code, Domäne und Produkt als Ganzem.
Sollten Sie bereits Probleme mit einer alten problematischen Codebasis haben oder diese künftig vermeiden wollen und sicherstellen wollen, dass Ihr Produkt professionell gestaltet wird, kontaktieren Sie uns bei Chudovo. Wir sind ein zuverlässiges Beratungsunternehmen mit fast zwei Jahrzehnten Markterfahrung, haben hunderte erfolgreiche Projekte weltweit abgeschlossen und freuen uns darauf, Ihr Projekt zu unterstützen!