Der Aufstieg der KI in der сloud-nativen Softwareentwicklung
Die Integration von Künstlicher Intelligenz (KI) in Software begann bereits Mitte der 1950er Jahre, also vor über 70 Jahren. Ursprünglich hat man KI eingesetzt, um die intelligenten Systeme zu entwickeln und Probleme zu lösen, für die herkömmliche Algorithmen nicht ausreichend waren. Von der Mustererkennung in Mediendateien bis hin zu vollständig interaktiven KI-Chatbots haben sich die potenziellen Anwendungsbereiche von KI in der Softwareentwicklung in der akademischen Forschung rasant erweitert.
Angesichts der zahlreichen Fortschritte in der KI-Forschung hat man in Produkte, die KI und Cloud-Architektur investiert, um Probleme zu lösen. Heute werden viele Geschäftsanwendungen mithilfe der KI-Workflows und der Cloud-Infrastruktur betrieben. Beispielsweise kann man Empfehlungssysteme entwickeln und Produkte empfehlen, indem man Azure AI Foundry Large Language Model (LLM) und andere Services wie .NET Serverless Funktionen und Datenbanken verwendet. Ein konkretes Anwendungsbeispiel wird in den folgenden Abschnitten erläutert.
Integration von KI mit .NET und Azure Cloud
Ein zentrales Element der KI-basierten .NET Cloud-Architektur unseres Empfehlungssystems ist ein Prompt. Ein Prompt ist eine Kommunikationsform mit dem LLM. So kann beispielsweise der Azure AI Foundry Cloud-Service aufgefordert werden, eine Liste empfohlener Produkte auf Basis früherer Käufe und Präferenzen eines Kunden zu generieren.
Viele Modelle könnten jedoch ineffektive Antworten geben, wenn die Eingabedaten nicht richtig verarbeitet werden, der Prompt nicht korrekt formuliert ist oder das LLM keine kontextuellen Informationen gefunden hat.
Prompt Engineering in der Cloud Integration
Die Interaktion zwischen Nutzer/Entwickler und LLM erfolgt über einen Prompt. Das LLM verarbeitet die Anfrage und sucht in seiner internen Datenbank nach der besten Antwort. Unklare Anweisungen können jedoch die Präzision der Antworten beeinträchtigen.
Um die Präzision zu verbessern und die Nutzererfahrung zu optimieren, nutzen wir Prompt-Engineering-Leitfäden von Azure OpenAI. Diese strukturieren den Prompt so, dass er für das LLM besser verständlich ist und die Wahrscheinlichkeit einer qualitativ hochwertigen Antwort steigt.
Beispielsweise ist Few-Shot-Prompting eine Technik, bei der dem LLM Beispiele für gute Antworten gegeben werden, um die Antwortmöglichkeiten einzuschränken. Zero-Shot-Prompting hingegen enthält keine Beispiele für ideale Antworten und überlässt die Entscheidung dem LLM.
Prompting lässt sich mit fast jeder Sprache integrieren, die HTTP-Aufrufe ermöglicht, da die meisten aktuellen KI-Modelle eine öffentliche API bieten. Es existieren auch Frameworks mit fertigen Integrationen für verschiedene LLMs, etwa das Azure OpenAI-Projekt für .NET oder das Spring AI-Projekt für Java, die Bibliotheken für die Interaktion mit Modellen wie GPT, Ollama und Mistral bereitstellen.
Prompt Engineering steht im Mittelpunkt unserer .NET Cloud-Architektur, um Nutzern präzise und personalisierte Produktempfehlungen zu geben.
Retrieval-Augmented Generation (RAG) und Cloud-Vector-Datenbanken
Retrieval Augmented Generation (RAG) bezeichnet den Prozess, wenn die Informationen aus einer Quelle extrahiert, in Token umgewandelt und an einem anderen Ort gespeichert werden. Beispielsweise kann man Daten aus einem Marketing-Buch in ein Dokumentenarchiv in Azure extrahieren und in Token umwandeln. Jeder Vektor repräsentiert dabei ein Wort oder einen ganzen Satz, je nachdem, wie der Text segmentiert wird. Anschließend können alle extrahierten Vektoren in einem Vektorspeicher wie Azure AI Search abgelegt werden. So steht die Buchinformation dem LLM in einem leicht verarbeitbaren Format zur Verfügung.
Nach dem Extrahieren, Transformieren und Laden kann man mittels Ähnlichkeitssuche Vektoren finden, die besonders hilfreich bei der Beantwortung der im Prompt formulierten Fragen sind. Nachdem das gesamte Buch in den Vektorspeicher geladen wurde, lassen sich wertvolle Marketing-Erkenntnisse daraus gewinnen, um bessere Produktempfehlungen anzubieten.
Serverless Functions mit Azure-Serverless-Diensten
Serverless Functions dienen dazu, Daten in latenzkritischen Pipelines zu validieren und zu transformieren. Beim Empfehlungssystem erfolgt der Prozess asynchron, was für diese Funktionalität vorteilhaft ist. Serverless Functions können als Validierungs- und Transformationseinheiten in solchen Workflows eingesetzt werden und das System wird dadurch kosteneffizient gestaltet.
So kann eine Serverless Function als Validator fungieren, deren einzige Aufgabe ist, Eingabedaten aus einer Datenquelle, einer Datenbank oder Benutzereingabe zu validieren. Die Reduzierung fehlerhafter Daten, die beim LLM eintreffen, verbessert dessen Genauigkeit.
Zusätzlich wandelt eine Transformer-Serverless Function die Eingabedaten in ein anderes Format um und erleichtert somit die Verarbeitung durch das LLM.
Eventgesteuerte Pipelines mit Azure Storage Queues
Das letzte Element der Cloud-Architektur sind Queues, die resiliente asynchrone Workflows ermöglichen. Mit Queues kann der Datentransfer zwischen Systemen mithilfe von Azure Storage Queues automatisiert werden. Ändert sich etwas in einer Datenbank, wird ein anderes System benachrichtigt, sodass entsprechende Maßnahmen ergriffen werden können. Kauft ein Kunde, zum Beispiel, ein Produkt, wird diese Information in einer relationalen Datenbank gespeichert, die automatisch unseren Empfehlungssystem-Workflow benachrichtigt. So wird sichergestellt, dass das LLM stets aktuelle Daten verwendet.
Ein reales Beispiel für eine Cloud-Architektur mit KI-Integration
Schauen wir uns nun an, wie die integrierte Cloud-Architektur ein Empfehlungsproblem löst. Nachfolgend finden Sie das High-Level-Diagramm der Cloud-Services und deren Verbindung.
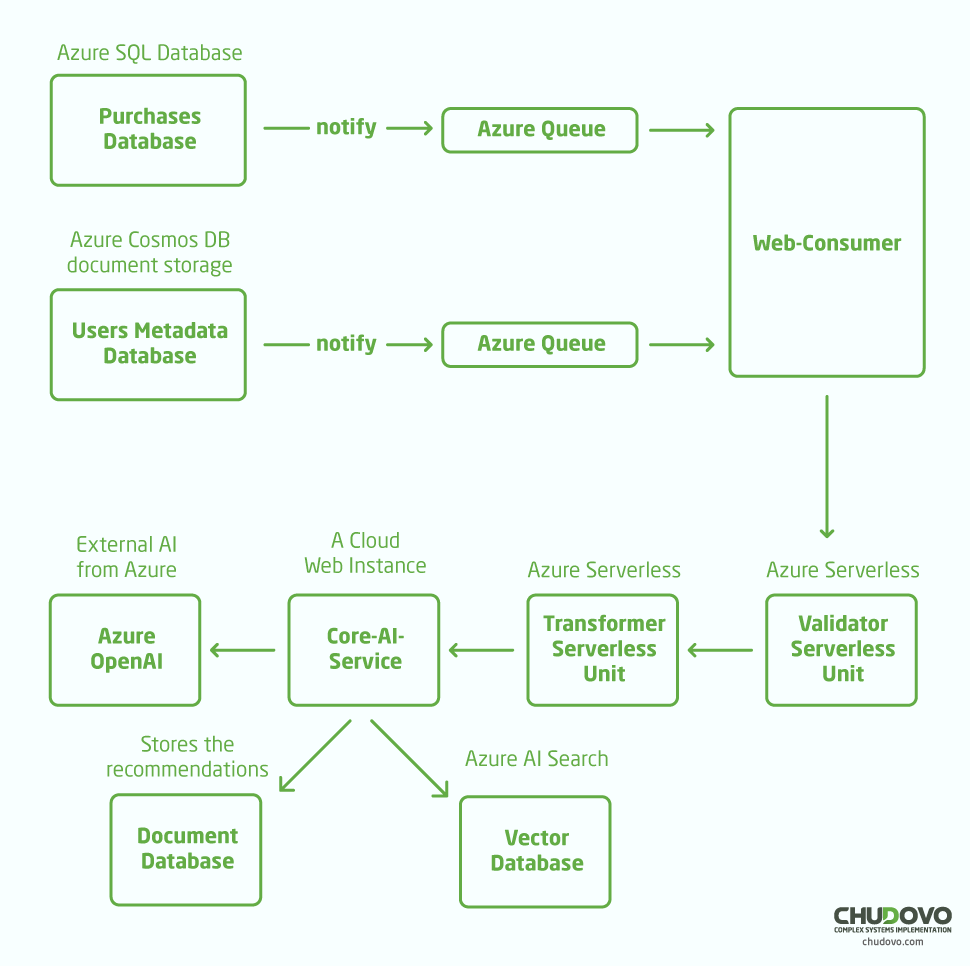
Lassen wir uns das Diagramm in eine Liste aufteilen, um es besser zu verstehen:
- Zunächst werden Daten aus einer Quelle erfasst. In unserem Fall stammen die Daten aus der zentralen Einkaufsdatenbank des Systems. Zusätzlich werden Metadaten zu Nutzerpräferenzen gesammelt, etwa wie oft der Nutzer das Produkt angesehen oder wie er das Produkt bewertet hat.
- Mit den Einkaufsdaten und Nutzerpräferenzen wird eine .NET Webanwendung asynchron über Azure Queues benachrichtigt.
- Die Web-Consumer-Anwendung empfängt Ereignisse aus beiden Datenbanken und startet die Serverless-Pipeline. Die erste Funktion validiert die Daten, z.B. hinsichtlich des erwarteten Formats. Die zweite Funktion transformiert die Daten in ein für die nächste Anwendung leichter verständliches Format, etwa von SQL-Relationen und CSV zu JSON.
- Der core-ai-service ist noch eine .NET Webanwendung, die mit Azure OpenAI, der Azure AI Search-Datenbank und einem weiteren Dokumentenarchiv zur Speicherung der Ergebnisse integriert ist.
- Zuerst wird eine Ähnlichkeitserkennung in Azure AI Search durchgeführt, um ähnliche Informationen aus der Datenquelle abzurufen. Beispielsweise könnten wir das zuvor erwähnte Marketing-Buch in Form von Vektoren gespeichert haben. So kann die KI Produktempfehlungen geben, die zum Autor des Buches passen
- Anschließend wird das Prompt an Azure OpenAI gesendet. Nach der Verarbeitung der Antwort wird das Ergebnis in einer Datenbank gespeichert, damit eine weitere Anwendung Zugriff darauf bekommt und die Empfehlungen abrufen kann.
Fazit
In diesem Beitrag haben wir veranschaulicht, wie sich eine einfache .NET Cloud-Architektur mit LLM aufbauen lässt, um die besten Produktempfehlungen (E-Commerce) anbieten zu können.
Kontaktieren Sie unser Team für umfassende Cloud App Entwicklung mit .NET.