Ereignisgesteuerte Architekturen (Kafka, RabbitMQ und mehr)
Einführung: Was ist eine ereignisgesteuerte Architektur? In der modernen Softwareentwicklung sind Microservices in der Regel die Standardlösung für den Aufbau skalierbarer, leistungsstarker und leicht wartbarer Software für Web-Plattformen und Systeme. Sie sind sowohl im Frontend als auch im Backend sehr gut einsetzbar, und heutzutage lassen sich diese verschiedenen Mikrosysteme zudem einfach warten und bereitstellen. In diesem Kontext ist die ereignisgesteuerte Architektur ein zentrales Element für die Kommunikation zwischen unterschiedlichen Services. In diesem Artikel erklären wir ereignisgesteuerte Systeme und ihre grundlegende Bedeutung für die Entwicklung moderner und wirtschaftlich nachhaltiger Weblösungen, die Ihren Kunden das beste Nutzererlebnis ermöglichen.
Wie ereignisgesteuerte Architektur funktioniert
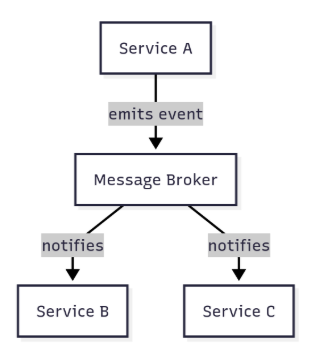
Die ereignisgesteuerte Architektur ist ein Architekturmuster, das Messaging-Services verwendet, um Informationen beim Auftreten eines Ereignisses an eine Queue weiterzuleiten. Diese Reihe der Ereignisse (Queue) verarbeitet anschließend die verschiedenen Nachrichten, und ein weiterer Service wird so konfiguriert, dass er über diese Reihe Kontrolle hat: er empfängt die Nachricht und verarbeitet sie weiter. Die Gesamtarchitektur besteht aus drei grundlegenden Services: Produzenten, Konsumenten und Event-Brokern.
Services, die die Ereignisse erzeugen und versenden, werden als Produzenten bezeichnet; Services, die die Ereignisse verarbeiten, sind die Ereignisverbraucher (oder Abonnenten). Schließlich gibt es den zwischengeschalteten Service, den sogenannten Ereignis-Router (oder Ereignis-Orchestrator). Er ist für die Übermittlung der Informationen und Ereignisse zwischen den verschiedenen Services zuständig und ist in der Regel ein Online-Service wie Kafka, RabbitMQ, AWS SQS und andere. Er leitet die Nachrichten weiter, interpretiert, wohin sie gesendet werden sollen, und übermittelt sie an das richtige Ziel, da die Services sehr häufig nicht direkt miteinander kommunizieren können. Dieses Schema veranschaulicht die Architektur:
Außerdem gibt es zwei Möglichkeiten, wie Anwendungen miteinander kommunizieren können: über Message Queues (der häufigste Weg) und über Pub/Sub-Architekturen. Erstere ist mehr oder weniger der Standard: Jede Nachricht wird an einen einzelnen Abonnenten gesendet und funktioniert wie eine Reihe von Aufgaben, die nacheinander verarbeitet werden müssen. Das Pub/Sub-Muster hingegen steht für „Publish/Subscribe“ und bedeutet, dass der Produzent Ereignisse zu einem bestimmten Thema veröffentlicht, und die Abonnenten darauf abonniert sind. Alle Abonnenten erhalten das Ereignis gleichzeitig. Dies ist besonders praktisch, wenn mehrere unterschiedliche Services Ereignisse aus einer einzigen Quelle erhalten müssen – ähnlich wie beim Rundfunk. Letztlich erfolgt alles über klar definierte und strukturierte Verträge, die von allen Abonnenten und Produzenten strikt eingehalten werden müssen, um Datenverlust, Beschädigung oder Fehlinterpretation zu vermeiden, sowie über Schemas, also Modelle, denen die Ereignisse folgen müssen.
Vorteile der ereignisgesteuerten Architektur
Der Einsatz der ereignisgesteuerten Architektur bietet verschiedene Vorteile. Vor allem ermöglicht es die Erstellung skalierbarer und leistungsfähiger Projekte, die mit modernen, aktuellen Stacks modelliert werden und leicht wartbar sowie skalierbar sind. Entwicklungszyklen werden schneller, sobald man den Umgang mit Ereignissen und die Kommunikation zwischen Services verinnerlicht hat; jede Funktion kann sicher und einfach an bestehende Systeme angebunden werden, ohne diese zu beeinträchtigen.
Des Weiteren ermöglicht es eine nächste Stufe der Echtzeit-Datenverarbeitung. Dies ist entscheidend für Web-Chats oder Live-Dashboards, bei denen Daten kontinuierlich aktualisiert werden müssen. Mit dieser Architektur können mehrere Abonnenten Ereignisse gleichzeitig empfangen, sodass unterschiedliche Datenbanken und Microservices gleichzeitig aktualisiert werden können. Sie ist auch die ideale Lösung für die Nutzererfahrung,da sie eine intuitive und störungsfreie Nutzung der Anwendung ermöglicht und so zu einer höheren Nutzerzufriedenheit führt.
In Anbetracht all dessen ist die ereignisgesteuerte Architektur definitiv eine sehr gute Option – und manchmal unerlässlich, um skalierbaren, flexiblen und leistungsfähigen Code für große Produkte zu entwickeln. Wenn Ihr Unternehmen Echtzeitdaten in großem Umfang verarbeiten muss, ist die Einführung dieser Architektur die richtige Wahl für Sie und Ihr Team.
Herausforderungen bei der Implementierung ereignisgesteuerter Systeme
Obwohl die ereignisgesteuerte Architektur viele Vorteile bietet, gibt es auch einige Herausforderungen und Nachteile für die Kommunikation zwischen verschiedenen Services. Wenn Sie beispielsweise Ihre ereignisgesteuerten Muster und Verträge nicht sorgfältig planen und strukturieren, werden Ihre Projekte sehr schnell unübersichtlich und chaotisch. Im Folgenden finden Sie eine kurze Übersicht über typische Probleme und Hinweise, wie Sie diese vermeiden können.
Komplexität bei der Nachverfolgung von Ereignissen
Da Ereignisse sehr häufig zwischen vielen verschiedenen Services „reisen“, kann es äußerst schwierig werden, nachzuvollziehen, woher etwas kommt und wohin es geht. Es wirkt fast wie „Magie“, da man während der Ausführung oft keine Kontrolle über den Ursprung und das Ziel der Ereignisse hat und diese komplett unkontrolliert gesendet und empfangen werden.
Um dieses Problem zu lösen, sollten Sie Logging-Techniken einsetzen: sowohl das Loggen in die Konsole für Debugging-Zwecke als auch das Speichern in einer Log-Tabelle in Ihrer Datenbank. Ein besonders wichtiger Aspekt dabei ist das Erstellen von Trace-IDs, sodass jedes Ereignis eine eindeutige UUID erhält. Beim Nachverfolgen können Sie so wertvolle Informationen erhalten, um sowohl zu verstehen, was passiert, als auch Fehler und Probleme in Ihren Anwendungen festzustellen.
Hier ein kurzer Tipp zur Umsetzung mit NodeJS unter Verwendung von RabbitMQ als Event-Broker:
/ install dependencies first:
// npm install amqplib uuid
import amqp from 'amqplib';
import { v4 as uuidv4 } from 'uuid';
function log(service, message, traceId) {
console.log(`[${new Date().toISOString()}] [${service}] [trace:${traceId}] ${message}`);
}
// Producer – sends event
async function producer() {
const connection = await amqp.connect('amqp://localhost');
const channel = await connection.createChannel();
const queue = 'orders';
await channel.assertQueue(queue, { durable: true });
const traceId = uuidv4();
const event = {
type: 'OrderCreated',
data: { orderId: 123, total: 49.9 },
traceId
};
channel.sendToQueue(queue, Buffer.from(JSON.stringify(event)));
log('Producer', `Event sent: ${event.type}`, traceId);
await channel.close();
await connection.close();
}
// Consumer – receives the event and registers logs
async function consumer() {
const connection = await amqp.connect('amqp://localhost');
const channel = await connection.createChannel();
const queue = 'orders';
await channel.assertQueue(queue, { durable: true });
log('Consumer', 'Waiting for messages...', '-');
channel.consume(queue, (msg) => {
if (msg !== null) {
const event = JSON.parse(msg.content.toString());
log('Consumer', `Event received: ${event.type}`, event.traceId);
log('InventoryService', `Updating inventory for order ${event.data.orderId}`, event.traceId);
channel.ack(msg);
}
});
}
// Start
consumer();
setTimeout(producer, 2000); // send event after two secondsSchwierigkeiten bei der Sicherstellung der Datenkonsistenz
In der Regel werden Datentypen nicht korrekt gepflegt und kontrolliert, wenn Informationen zwischen mehreren Systemen übertragen werden. Dieses Problem mit den Datentypen führt unweigerlich zu großen Inkonsistenzen im System. Ihre Softwarelösungen können sogar vollständig versagen, sobald unerwartete oder falsch formatierte Daten eintreffen. Um dies zu vermeiden, sollten Sie sehr genau planen, wie Sie Ihre Events implementieren und wie diese in allen Umgebungen und Services typisiert werden, sodass die Informationen innerhalb des Events zuverlässig und korrekt sind.
Größere Lernkurve
Die ereignisgesteuerte Architektur ist anfangs etwas verwirrend und schwer nachvollziehbar. Es wirkt, als würde das Event „magisch“ in Ihrem Service erscheinen oder als würde es in ein schwarzes Loch für immer gesendet werden. Es dauert eine Weile, bis man die Funktionsweise wirklich verstanden hat. Deshalb erfordert die Eingewöhnung in diese Architektur mehr Zeit, und Entwicklungs- sowie Debugging-Prozesse sind zu Beginn langsamer.
Notwendigkeit der Versionierung von Event-Schemas
Schließlich ist es sehr wichtig, Event-Schemas zu versionieren. Mit der Weiterentwicklung und zunehmenden Komplexität der Systeme müssen einige Events geändert, aktualisiert oder refaktoriert werden. Ohne ordnungsgemäße Versionierung treten Fehler auf, da Ihre Systeme nicht synchronisiert sind, um dieselbe Datenstruktur und Event-Typen zu verarbeiten. Dies kann dazu führen, dass alte Events fehlerhaft interpretiert werden. Dieses Problem kann sich auch auf andere Teile Ihres Projekts ausweiten: Ohne Versionierung funktionieren Audit-Logs möglicherweise nicht mehr, Systemberichte werden unzuverlässig, und teilweise wird die Kommunikation vollständig unterbrochen.
Schritt-für-Schritt-Anleitung für den Aufbau ereignisgesteuerter Anwendungen
Die grundlegende Funktionsweise ereignisgesteuerter Anwendungen wurde bereits erklärt, allerdings bislang eher abstrakt dargestellt. Hier folgt ein kurzer Praxis-Tutorial zur ereignisgesteuerten Architektur, mit einer Einführung in die praktische Implementierung einer ereignisgesteuerten Anwendung unter Verwendung von RabbitMQ als Event-Broker und Node.js für die Services.
- Events und Produzenten definieren
Dies ist die Planungsphase, in der Sie festlegen, welche funktionalen Code-Bausteine Events an den Broker senden müssen. Wenn Sie beispielsweise ein Checkout-System entwickeln, möchten Sie wahrscheinlich andere Services informieren, wenn eine Zahlung bestätigt oder ein Kauf vom Kunden storniert wird.
- Einen Message Broker wählen (Kafka, RabbitMQ etc.)
Es gibt verschiedene Optionen. Einige können selbst gehostet werden, wie Apache Kafka oder RabbitMQ, andere werden von Anbietern als Platform-as-a-Service-Lösung angeboten, z. B. AWS SQS. Bei den beiden Optionen ist Kafka typischerweise die Wahl für Streaming oder große Datenmengen, während RabbitMQ eine einfachere, aber zuverlässige Lösung für Queuing darstellt.
- Abonnenten einrichten
Dies sind die Services, die die Events erkennen und darauf reagieren. Sie übernehmen die Aufgaben wie das Versenden von E-Mails, die Verarbeitung von Lagerbeständen oder das Protokollieren von Logs.
- Fluss testen und überwachen
Um sicherzustellen, dass alles funktioniert, sollten Sie Ihre Lösung mehrfach testen, den Prozessfluss nachvollziehen und nach Blockaden oder potenziellen Unterbrechungen in der Kommunikation zwischen den Services suchen.
Das folgende Beispiel zeigt eine ereignisgesteuerte Architektur mit NodeJS und RabbitMQ:
/ Publisher
const amqp = require("amqplib");
async function publish() {
const conn = await amqp.connect("amqp://localhost");
const ch = await conn.createChannel();
const queue = "orders";
await ch.assertQueue(queue);
ch.sendToQueue(queue, Buffer.from("OrderCreated: #123"));
console.log("Event published!");
}
// Consumer
async function consume() {
const conn = await amqp.connect("amqp://localhost");
const ch = await conn.createChannel();
const queue = "orders";
await ch.assertQueue(queue);
ch.consume(queue, (msg) => {
console.log("Received:", msg.content.toString());
});
}Wie man sieht, importiert der Code die Bibliothek, die RabbitMQ integriert. Anschließend wird eine Funktion namens publish erstellt, die eine Verbindung zum Event-Broker herstellt, einen Channel anlegt und ihn „orders“ nennt. Zum Schluss wird ein Event an die Queue gesendet.
Die Funktion consume geht am Anfang ähnlich vor. Am Ende registriert sie sich jedoch als Abonnent für die Queue, erkennt neue Ereignisse und protokolliert den Inhalt der empfangenen Nachricht in der Konsole.
Das ist also die grundlegende Funktionsweise eines ereignisgesteuerten Systems. Sie zeigt, wie einfach sich die Event-Verarbeitung skalieren und erweitern lässt, um unterschiedliche Aufgaben für Ihre Anwendung zu erfüllen.
Fazit
Zusammengefasst erklärt die ereignisgesteuerte Architektur, wie verschiedene Systeme miteinander kommunizieren können. Dafür kommen entweder einfache Queueing-Methoden oder das Pub/Sub-Pattern zum Einsatz. Erstere werden verwendet, um FIFO-Queues zu erstellen, die die Informationen sequenziell verarbeiten. Letzteres eignet sich für das Verteilen von Nachrichten, wenn mehrere Services dieselben Informationen benötigen.
Die Architektur basiert im Wesentlichen auf drei Komponenten: dem Produzenten, dem Event-Broker und dem Abonnenten. Der Produzent erzeugt ein Ereignis und übergibt es an den Broker. Dieser leitet das Event weiter, und der Abonnent empfängt es und verarbeitet die enthaltenen Informationen.
Nachdem Sie nun verstanden haben, wie die ereignisgesteuerte Architektur funktioniert, können Sie sie in Ihrer Software einsetzen und Ihr Produkt auf das höhere Niveau bringen. Die Architektur macht Anwendungen deutlich skalierbarer und entspricht modernen Entwicklungsstandards. Vergessen Sie nicht, dass die Wahl des passenden Event-Brokers eine zentrale Rolle spielt. Apache Kafka, RabbitMQ, AWS SQS und andere haben jeweils ihre Stärken und Schwächen. Die Unterschiede werden oft erst im Detail und im täglichen Einsatz deutlich. Jetzt sind Sie dran: Bauen Sie etwas Großartiges und Leistungsstarkes mit dieser hilfreichen Architektur. Anfragen Sie Architektur Beratung für Ihre IT-Projekte bei Chudovo!