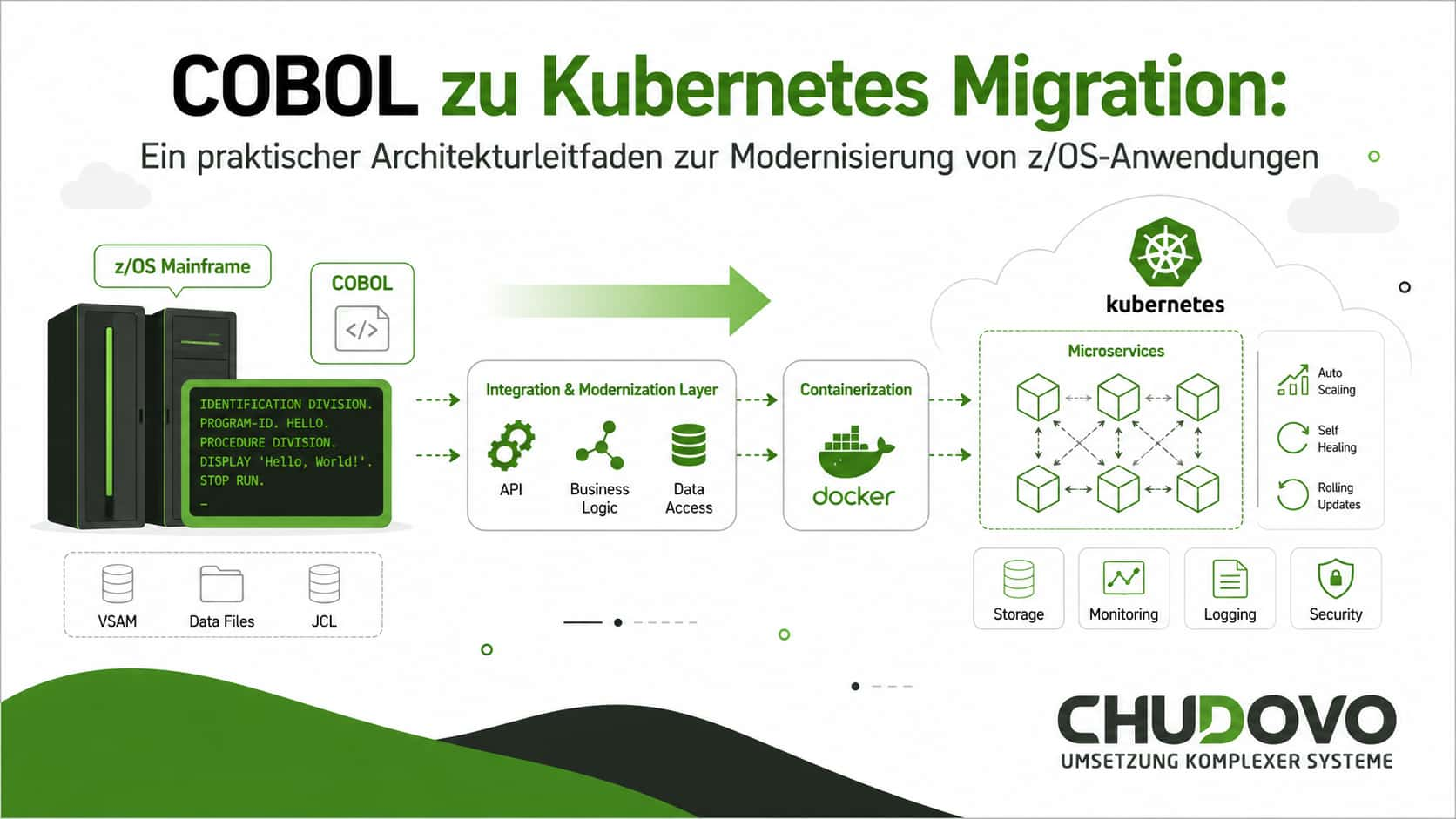
Von fragmentierten Systemen zur einheitlichen Architektur: Aufbau von Enterprise-Integrationsschichten
Die meisten großen Unternehmen haben ein CRM-System. Mit der Weiterentwicklung des Geschäfts kommen ein ERP hinzu, dann ein Data Warehouse, einige interne Tools und vielleicht auch eine Analyseplattform von Drittanbietern. Jede Ergänzung war zu ihrer Zeit sinnvoll.
Fünf Jahre später weiß niemand mehr genau, was mit den Kundendaten passiert, wenn sie im CRM aktualisiert werden. Genau das geschieht, wenn es keinen klaren Plan für eine Enterprise-Integrationsarchitektur gibt.
Ein solcher Plan hat nicht das Ziel, all diese Tools vollständig zu ersetzen. Der Hauptzweck besteht darin, eine Integrationsschicht aufzubauen, die all diese Systeme miteinander verbindet, und löst sich von einer starren Architektur mit Punkt-zu-Punkt-API-Abhängigkeiten.
In den folgenden Abschnitten erläutern wir, wie das Team von Chudovo diesen Plan mithilfe folgender Elemente umsetzt:
- Event-Busse
- Middleware
- Strategien zur Datenkonsistenz
- Sicherheit
Wir erläutern die Vor- und Nachteile jedes dieser Ansätze. Diese Muster gelten unabhängig davon, ob Sie Kafka, RabbitMQ, EventBridge oder eine maßgeschneiderte Lösung verwenden. Die Wahl des Anbieters ist weniger entscheidend, als die richtige Struktur der Schicht zu gestalten.
Event-Bus-Architektur
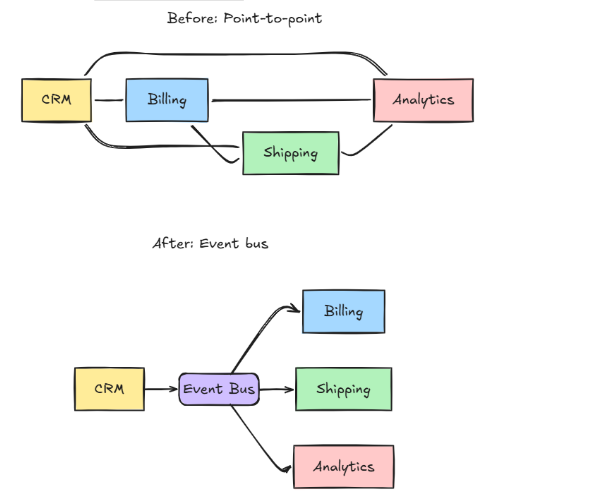
Hier ist ein Beispiel für eine sogenannte Punkt-zu-Punkt-Integration:
Service A ruft die API von Service B auf.
B überträgt Daten über einen Webhook an C.
C schreibt in eine gemeinsame Datenbank, aus der D liest.
In einer solchen Architektur hängt jeder Service von mindestens einem anderen Service ab.
Das funktioniert eine Zeit lang. Nachdem Sie den dritten oder vierten Service hinzugefügt haben, stellen Sie fest, dass jede neue Integration die Anzahl der zu wartenden Verbindungen verdoppelt.
Betrachten wir nun einen alternativen Ansatz: Anstatt dass Service A Service B direkt aufruft, veröffentlicht A bestimmte Informationen auf einem zentralen Bus. Jeder Service, der diese Daten benötigt, greift diese Informationen auf und verarbeitet sie nach seinen eigenen Regeln.
Das ist das Grundprinzip der Event-Bus-Architektur. Die „Information“, um die es dabei geht, wird als Ereignis (Event) bezeichnet.
 Nehmen wir ein CRM, das jedes Mal ein Ereignis auslöst, wenn sich die Rechnungsadresse ändert
Nehmen wir ein CRM, das jedes Mal ein Ereignis auslöst, wenn sich die Rechnungsadresse ändert
{
"event": "customer.address_updated",
"customerId": "cust_8812",
"timestamp": "2024-11-14T09:22:00Z",
"payload": {
"addressLine1": "742 Evergreen Terrace",
"city": "Springfield",
"country": "US"
}
}Dieses Ereignis wird einmal veröffentlicht. Jedes System, das eine solche Änderung benötigt, abonniert customer.address_updated.
Nach dem Empfang verarbeitet jeder Consumer das Ereignis im eigenen Kontext und in eigenem Tempo, mit eigener Retry- und Fehlerlogik. Das CRM hat keine Informationen über diese Systeme.
Wie Sie sehen, liegt der Hauptvorteil in der Unabhängigkeit der Systeme. Der Event-Produzent (Systemkomponente) ist ausschließlich für die Veröffentlichung des Ereignisses verantwortlich. Jedes System, das daran angebunden ist, übernimmt die eigene Logik. Wenn ein neuer Consumer hinzukommt, bleibt der Produzent unverändert. Fällt ein Consumer während der Verarbeitung aus, läuft der Produzent weiter.
Dabei gibt es jedoch einen wichtigen Aspekt zu beachten. Ein Ereignis kann vom Consumer 200 ms nach der Veröffentlichung verarbeitet werden oder erst 30 Sekunden später, wenn das System ausgelastet ist. Für einen Service, der eine synchrone und konsistente Antwort benötigt, ist ein direkter Aufruf oft die bessere Wahl.
Middleware-Strategie: Was gehört in die Integrationsschicht
Middleware wird oft als „Komponente zum Weiterleiten von Nachrichten“ verstanden. Tatsächlich deckt diese Architektur jedoch deutlich mehr Aufgaben ab.
In Unternehmenssystemen gibt es mehrere querschnittliche Anforderungen, die nicht von einzelnen Services separat umgesetzt werden sollten. Eine Aufgabe einer gut gestalteten Middleware-Architektur ist es, diese Anforderungen zu bündeln und durchzusetzen.
Eine Middleware-Schicht erfüllt in der Regel folgende Aufgaben:
- Weiterleitung und Transformation von Nachrichten. Sie wandelt ein Ereignis aus dem Schema eines Systems in das Schema eines anderen Systems um. Dabei kann ein Schema Registry genutzt werden, um Kompatibilität sicherzustellen und Fehler in nachgelagerten Systemen zu vermeiden.
- Protokoll-Übersetzung, sodass Systeme mit unterschiedlichen Kommunikationsstandards miteinander interagieren können.
- Laststeuerung und Backpressure. Die Middleware schützt nachgelagerte Services vor Überlastung.
- Dead-Letter-Handling. Ereignisse, die nicht verarbeitet werden konnten, werden erfasst und zur Analyse weitergeleitet.
- Observability. Zentrale Protokollierung, Tracing und Alerting über alle Nachrichtenflüsse hinweg.
Was nicht in die Middleware gehört, ist fachliche Logik. Welche Bedeutung ein CustomerUpdated-Ereignis für die Abrechnung hat, liegt außerhalb ihres Verantwortungsbereichs. Sie transformiert und leitet weiter, interpretiert aber nicht.
Enterprise-Messaging-Systeme: ESB vs. Lightweight Broker
Lange Zeit war das dominante Muster der Enterprise ein Service Bus (ESB). Dies ist eine zentralisierte Plattform, die Routing, Transformation, Orchestrierung und weitere Aufgaben erfüllt.
Auch wenn dieser Ansatz gut funktioniert, bringt er häufig zusätzliche Probleme mit sich. Jede neue Integration erfordert eine Änderung an der zentralen Bus-Konfiguration, was meist ein separates Team und einen neuen Freigabeprozess erfordert.
Aufgrund der Kommunikationsmuster von Microservices hat sich ein anderer Ansatz etabliert: leichtgewichtige Message Broker (Kafka, RabbitMQ, AWS EventBridge, Google Pub/Sub) in Kombination mit schlanken, zweckgebundenen Consumern. Jeder Service verwaltet seine eigene Abonnement-Logik. Der Broker übernimmt die Zustellung, Persistenz und eine garantierte Reihenfolge von Nachrichten.
Im Folgenden ein kurzer Vergleich beider Ansätze:
| Dimension | Enterprise Service Bus | Lightweight Message Broker |
| Zentralisierung | Hoch | Niedrig |
| Betriebsaufwand | Höher, oft mit eigenem dedizierten Team | Niedriger pro Team, insgesamt jedoch mehr Koordinationsaufwand |
| Transformation | Integriert | DIY oder über separaten Transformationsservice |
| Skalierung | Vertikal, oft begrenzt | Horizontal, auf hohen Durchsatz ausgelegt |
| Passt am besten | Regulierte Branchen, Legacy-Integration | Cloud-native Umgebungen, Microservices-orientierte Organisationen |
Mit einem Message Broker liegt die Verantwortung für die Integration wieder bei den Teams, die die Services betreuen. Je nach Organisation kann das entweder eine Verbesserung sein oder zusätzlichen Aufwand verursachen.
Datenkonsistenz in verteilten Systemen
Starke Konsistenz zwischen unabhängigen Services ist nur möglich, wenn man die Verfügbarkeit oder Systemstabilität einschränkt. Das ist als CAP-Theorem bekannt, und auch ausgefeilte Tools ändern daran nichts. Was möglich ist: gezielt Konsistenzgarantien dort festlegen, wo sie wichtig sind, und an anderen Stellen Eventual Consistency akzeptieren.
Outbox-Pattern
Angenommen, Sie aktualisieren einen Datenbankeintrag und möchten anschließend ein Event veröffentlichen. Wenn das Senden des Events nach dem Schreiben in die Datenbank fehlschlägt, entsteht eine stille Inkonsistenz. Eine der besten Strategien zur Datensynchronisation in eventgetriebenen Architekturen, um dieses Problem zu lösen, ist die transaktionale Outbox.
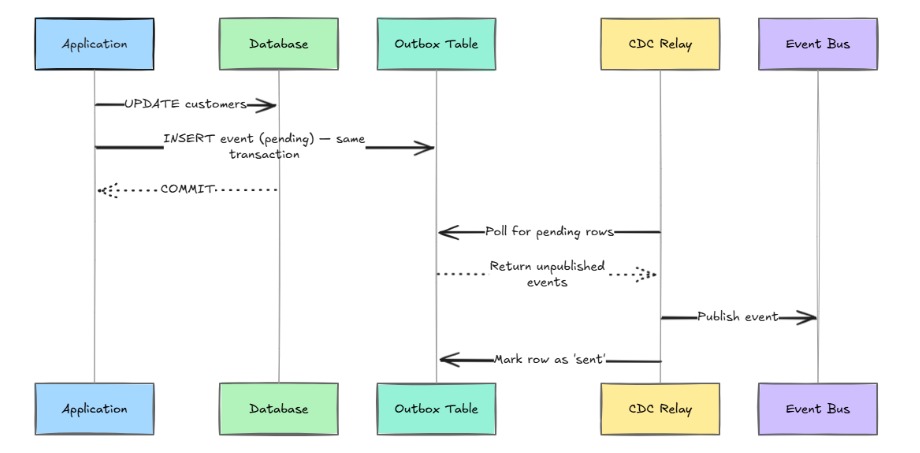
Wenn Sie den oben beschriebenen Ansatz befolgen, wird Ihr Event genau dann veröffentlicht, wenn das Schreiben in der Datenbank erfolgreich ist.
-- Application writes both in one transaction
BEGIN;
UPDATE customers SET address = $1 WHERE id = $2;
INSERT INTO outbox (event_type, payload, status)
VALUES ('customer.address_updated', $3, 'pending');
COMMIT;
-- CDC relay picks up pending outbox rows and publishes them
-- Marks rows 'sent' after successful publishEs gibt allerdings einen Kompromiss. Sie brauchen einen zuverlässigen CDC-Relay-Prozess, und bei jedem Schreibvorgang, der ein Event veröffentlichen soll, kommt eine zusätzliche Tabelle hinzu. Für die meisten Teams lohnt sich dieser Aufwand wegen der sicheren Konsistenz.
Idempotenz
Die meisten Messaging-Systeme im Unternehmensumfeld garantieren eine mindestens einmalige Zustellung, nicht genau einmal. Das bedeutet, dass Consumer doppelte Events sauber verarbeiten müssen. Der übliche Ansatz ist, jedem Event einen Idempotenzschlüssel mitzugeben und zu speichern, welche Schlüssel bereits verarbeitet wurden. Der zweite Durchlauf hat dann keine Wirkung.
Zum Beispiel:
-- Idempotency guard in the consumer handler
CREATE TABLE processed_events (
event_id TEXT PRIMARY KEY,
processed_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
BEGIN;
INSERT INTO processed_events (event_id)
VALUES ($1)
ON CONFLICT (event_id) DO NOTHING;
-- 0 rows inserted = duplicate event, skip in application layer
COMMIT;Es gibt jedoch einige echte Sonderfälle, die Sie beachten sollten. Wenn die Verarbeitung zum Beispiel externe Aktivitäten voraussetzt, wie das Versenden einer E-Mail oder das Abbuchen einer Zahlung, müssen Sie die Idempotenz in der Regel im nachgelagerten System selbst sicherstellen, nicht nur im Event-Handler.
Sicherheitsmodell für die Integration von Enterprise-Systemen
Die sichere Integration von Enterprise-Systemen ist anspruchsvoller als die Absicherung einzelner Services. Das liegt einerseits an der größeren Angriffsfläche und andererseits daran, dass Integrationsschichten oft weniger intensiv geprüft werden als die Systeme, die sie verbinden.
Aus unserer Erfahrung wird die Autorisierung auf Topic-Ebene am häufigsten ausgelassen. Teams beschränken zwar, wer sich mit dem Broker verbinden darf, lassen aber Topic-Abonnements weitgehend offen. Das wird als ACL-Gap bezeichnet.
Wenn ein Service ein Topic lesen kann, sieht er alle Events darin, auch solche mit personenbezogenen oder finanziellen Daten. Wird das ignoriert, kann es zu Datenlecks und großen Sicherheitsproblemen kommen.
Weitere wichtige Sicherheitsaspekte sind:
- Kurzlebige Service-Zugangsdaten
- TLS für die Übertragung
- Feldbasierte Verschlüsselung für sensible Nutzdaten
- Audit-Logging
Der ACL-Gap ist jedoch der Bereich, in dem höchstwahrscheinlich reale Sicherheitslücken auftreten.
Authentifizierung und Autorisierung auf Bus-Ebene
Oft wird für die Authentifizierung die Integration mit Ihrer Identity- und Access-Management-Architektur genutzt, um servicespezifische Tokens auszustellen, zum Beispiel über OAuth 2.0 Client-Credentials oder Workload-Identitäten in Cloud-Umgebungen. Jeder Service, der Events veröffentlicht oder abonniert, sollte sich mit kurzlebigen Zugangsdaten am Event-Bus authentifizieren. Langfristige API-Schlüssel in Konfigurationsdateien sollten vermieden werden.
Als Faustregel gilt: Autorisierung muss explizit sein. Service A darf nur Topics veröffentlichen, die ihm gehören, und nur solche abonnieren, für die er ausdrücklich freigeschaltet wurde. Standardmäßig sollte alles verboten sein, nicht erlaubt.
Zu großzügige Topic-Abonnements führen häufig dazu, dass falsch konfigurierte oder fehlerhafte Services Daten erhalten, auf die sie keinen Zugriff haben sollten. Deshalb ist diese Regel wichtiger, als sie zunächst wirkt.
Verschlüsselung und Datenklassifizierung
Events sollten während der Übertragung verschlüsselt sein, mindestens mit TLS 1.2, besser TLS 1.3. Für sensible Daten empfiehlt sich zusätzlich eine feldbasierte Verschlüsselung innerhalb des Event-Payloads. So bleiben einzelne Felder geschützt, selbst wenn jemand unbefugten Zugriff auf den Speicher des Message-Brokers erhält.
Beispiele dafür sind:
- Alle Daten mit Personenbezug
- Finanzdaten
- Gesundheitsdaten
Es ist ratsam, Event-Typen von Anfang an zu klassifizieren. Eine Produktkatalog-Änderung hat eine geringe Sensibilität, eine Zahlungsaktualisierung eines Kunden ist dagegen hochsensibel. Einheitliche Sicherheitsmaßnahmen für alle Fälle sind teuer und führen oft dazu, dass Teams Kompromisse eingehen. Setzen Sie Maßnahmen passend zur jeweiligen Klassifizierung ein.
Audit-Logging
Ihre Integrationsschicht ist ein idealer Ort für Audit-Logging, denn sie bietet eine vollständige Übersicht über den Datenfluss zwischen allen Systemen .
Dabei sollten nicht nur Fehler erfasst werden, sondern auch reguläre Prozesse. Beispiele für sinnvolle Logs sind:
- Wer, wann, welche Events, auf welche Topics veröffentlicht hat
- Bestätigungen durch Consumer
Das ist nicht nur für Compliance wichtig, sondern auch eine gute Möglichkeit, nachträglich Probleme mit Dateninkonsistenzen zu analysieren.
Typische Fehlerszenarien in Enterprise-Integrationsschichten
Vorhersehbare Fehlerszenarien können selbst in gut gestalteten Integrationsplattformen auftreten. Einige davon zeigen sich nicht als offenkundige Fehler, sondern als subtile Dateninkonsistenzen oder unerklärliches Systemverhalten:
- Schema-Drift: Wenn ein Produzent ein Feld umbenennt oder einen Typ ändert, ohne vorher abzustimmen, parsen Verbraucher unhörbar falsche Daten oder kriegen unklare Fehlermeldungen. Um das zu verhindern, implementieren Sie ein Schema-Registry, das Kompatibilitätsprüfungen zur Veröffentlichungszeit durchführt.
- Consumer-Lag: Dies tritt auf, wenn ein langsamer Verbraucher einen großen Backlog ansammelt. Das kann zu echten Konsistenzproblemen führen. Kontrollieren Sie Consumer-Lag als primäres Metrik, nicht als Nebenaspekt.
- Zirkuläre Event-Loops: Nehmen Sie Service A, der ein Event veröffentlicht, das Service B zum Aktualisieren eines Records veranlasst. Diese Aktualisierung löst wiederum ein erneutes Veröffentlichen durch Service A aus. Das kann sich unendlich wiederholen. Um das zu verhindern, integrieren Sie Metadaten wie Causation- und Correlation-IDs. Verbraucher sollten keine Events weiter veröffentlichen, die aus ihren eigenen Aktionen stammen.
- Outbox-Table-Bloat: Wenn ein CDC-Relay zurückfällt oder ausfällt, wird die Outbox-Tabelle unendlich groß. Kontrollieren Sie die Outbox-Tabellengröße und Relay-Gesundheit unabhängig von der Kernapplikation.
Zusammengefasst: Eine echte Service-Integrationsschicht
Das Design einer einheitlichen Enterprise-Systemarchitektur erfordert nicht den Austausch bestehender Systeme. Es erfordert die Einführung einer kohärenten Schicht dazwischen. Mindestens umfasst diese Schicht:
- Ein Message Broker mit langlebiger Speicherung, konfigurierbarer Retention und Consumer-Group-Unterstützung.
- Ein Schema-Registry, das Event-Verträge zwischen Produzenten und Verbrauchern durchsetzt.
- Eine Middleware-Schicht für Routing, Transformation und Protokoll-Brücken (keine Business-Logik).
- Eine zentrale Übersicht über Pipeline-Gesundheit, die Event-Engpässe, Fehler und Gesamtbearbeitungszeit überwacht.
- Eine klare Sicherheitsarchitektur mit gegenseitiger Authentifizierung, topic-basierter Autorisierung und Audit-Logging.
Beginnen Sie dort, wo Ingenieure die meiste Zeit mit dem Debuggen von Dateninkonsistenzen oder der Pflege fragiler API-Verbindungen verbringen. Bauen Sie die Integrationsschicht zuerst auf, machen Sie sie funktionsfähig und beobachtbar, dann erweitern Sie sie.
Das Ziel ist nicht, Ihre Systeme von außen einfach aussehen zu lassen. Das Ziel ist, die Komplexität an einen Ort mit klaren Grenzen zu verlagern: Wo sie isoliert getestet, mit echten Metriken gemessen und ohne Kontext von sechs verschiedenen Teams verstanden werden kann. Das ist eine echte Enterprise-Integrationsarchitektur, die sich tatsächlich umsetzen lässt.