Was ist DeepSeek und warum hat es den Markt plötzlich erobert?
Das hochmoderne KI-Modell DeepSeek-R1 wurde erst letzte Woche veröffentlicht, doch es hat den Markt blitzschnell erobert. Aber wie und warum? Hier erfahren Sie es!
Der KI-Markt gehört zu den volatilsten und spekulationsreichsten Branchen der letzten Jahre. Unternehmen wie OpenAI, Anthropic und Meta haben Hunderte Millionen Dollar investiert und in den vergangenen drei Jahren unzählige Modelle geschaffen. Dies hat die Aktien vieler Unternehmen – allen voran Nvidia – stark steigen lassen und ihre Marktkapitalisierung auf mehrere Billionen Dollar erhöht. Zudem hat die KI-Revolution den Technologiemarkt grundlegend verändert, da sie enorme technische und infrastrukturelle Anforderungen mit sich bringt. So wird beispielsweise bei Microsoft und Meta geplant, stillgelegte Atomkraftwerke wieder hochzufahren, um ihren Energiebedarf zu decken. Auch KI-Ingenieure zählen derzeit zu den bestbezahlten Fachkräften.
Doch in der vergangenen Woche hat ein neues großes Sprachmodell, DeepSeek-R1, entwickelt von Hangzhou DeepSeek Artificial Intelligence, die Branche erschüttert. Bisher gab es eine Annahme, dass leistungsfähige KI-Modelle eine immense Infrastruktur benötigen – sowohl für das Training als auch für den Betrieb und die Bereitstellung über APIs. DeepSeek-R1 hat dieses Paradigma jedoch widerlegt: Es erzielt auf Benchmark-Tests die gleiche Genauigkeit wie OpenAIs GPT-4o, kostet aber nur einen Bruchteil davon. Zudem wurde es mit einem deutlich kleineren Budget trainiert – ursprünglich als Nebenprojekt für andere Anwendungen.
Doch was steckt wirklich hinter dem Hype? Und wie schlägt sich DeepSeek-R1 im Vergleich zu anderen Modellen? Werfen wir einen genaueren Blick auf die Details!
Wie DeepSeek-R1 so schnell populär wurde
Es gibt viele Gründe, warum DeepSeek-R1 in einem Augenblick so viel Aufmerksamkeit erlangte. Das Modell wurde in den letzten Tagen so stark nachgefragt, dass es mehrfach DDoS-Angriffen ausgesetzt war, zeitweise offline ging und keine neuen Benutzer mehr aufgenommen werden konnten. Auch andere Malware-Angriffe wurden gemeldet. Doch was genau hat DeepSeek-R1 so populär gemacht?
- Es ist disruptiv: DeepSeek-R1 wurde unter extrem eingeschränkten Bedingungen entwickelt, da China aufgrund von US-Sanktionen keinen Zugang zu High-End-KI-Hardware wie der Nvidia H100 Tensor Core GPU hatte. Zudem sind einige KI-Entwicklungstools so konzipiert, dass sie nur auf Nvidia-GPUs optimal laufen, was den Zugang für DeepSeek zusätzlich erschwert. Um dieses Problem zu bewältigen, musste das Team innovative Methoden einsetzen – darunter verstärktes Lernen und kosteneffiziente Trainingsmethoden.
- Es liefert Spitzenleistung: Laut den auf der DeepSeek-R1-Seite bei Ollama veröffentlichten Benchmark-Tests erreicht das Modell eine Leistung, die mit den besten Modellen wie OpenAI-o1 vergleichbar ist. Auch die Nutzer bestätigen diese Ergebnisse: Viele berichten, dass DeepSeek-R1 in einigen Fällen sogar besser als ChatGPT ist. Insbesondere in der Entwickler-Community gilt es als eines der besten Modelle für Programmieraufgaben – oft leistungsfähiger als ChatGPT und auf Augenhöhe mit Claude. Ein großer Vorteil: DeepSeek bietet eine kostenlose Online-Chat-Version an, was bei Modellen wie Claude nicht der Fall ist.
- Es ist extrem günstig: Die hohen Betriebskosten von LLMs haben die SaaS-Branche in den letzten Jahren stark verändert. Während die Gewinnmarge früher bei 70 bis 80 % lag, ist sie heute auf 40 bis 50 % gesunken. DeepSeek setzt hier neue Maßstäbe: Es kostet nur $0.15 pro Million Eingabetoken, während ChatGPT $2.50 pro Million Eingabetoken verlangt – eine Kostenersparnis von 94 %. Da KI für Unternehmen mittlerweile unverzichtbar ist, verschafft das einen erheblichen Wettbewerbsvorteil
- Es hat fast den Aktienmarkt erschüttert: Der Hype um DeepSeek-R1 hatte so große Auswirkungen, dass der US-Aktienmarkt darauf reagierte. Nvidia-Aktien fielen um etwa 15 %, und der KI-Markt hat bereits über eine Billion Dollar an Wert verloren. Der Grund: DeepSeek-R1 widerlegte viele bisherige Annahmen – insbesondere, dass leistungsstarke KI-Modelle enorme infrastrukturelle Kosten verursachen müssen. Selbst OpenAI-CEO Sam Altman räumte öffentlich ein, dass er nun intensiv daran arbeitet, seine Modelle günstiger zu machen. Gleichzeitig gibt es Berichte, dass Meta mehrere „War Rooms“ eingerichtet hat, um DeepSeek zu analysieren und herauszufinden, wie es so günstig und gleichzeitig so leistungsstark sein kann.
In einem Markt, der ohnehin für Innovation und Wettbewerb bekannt ist, hat DeepSeek-R1 die Konkurrenz herausgefordert und die führenden Unternehmen unter Druck gesetzt. Der größte Gewinner? Wir, die Nutzer, die nun von den besten Ergebnissen profitieren und gleichzeitig weniger zahlen – ein erheblicher Vorteil durch die neue Konkurrenz.
Wie es trainiert wurde
Ein tieferer Blick auf das Training von DeepSeek-R1 und was es so innovativ macht: Hier sind einige der Methoden, die dabei verwendet wurden:
- Verstärkendes Lernen aus menschlichem Feedback (RLHF): Es werden tiefe neuronale Netzwerke für das Training genutzt, wobei gleichzeitig menschliches Feedback berücksichtigt wird. Dadurch entsteht ein Belohnungsmodell, das das Gelernte verstärkt.
- Komprimierungs- und Quantisierungstechniken: Das Modell wird komprimiert, was die Größe verringert, ohne die Leistung und Qualität zu beeinträchtigen. Zudem wurde eine Pruning-Technik verwendet, um weniger wichtige Teile des neuronalen Modells zu entfernen, was die Komplexität reduziert.
- Verwendung synthetischer Daten: Es werden von anderen Modellen generierte Daten verwendet, was die Kosten und den Aufwand für die Extraktion neuer Daten aus menschlichen Quellen senkt. Diese Methode war umstritten, da OpenAI DeepSeek beschuldigt hat, die Antworten ihres Modells gestohlen zu haben, um das eigene zu trainieren.
- Transferlernen: Anstatt von Grund auf zu lernen, erhielt R1 Informationen aus früheren Modellen. Das Modell wurde zuerst mit allgemeinen Aufgaben trainiert und später gezielt weiterentwickelt, wodurch Zeit und Kosten gespart wurden.
- Verfeinerung: Die ersten Datensätze, die vom Modell generiert wurden, wurden etikettiert und bewertet, was die Leistung und Lesbarkeit für Menschen verbesserte.
Diese und einige andere Praktiken haben R1 zu einem leichten Modell gemacht, das kostengünstig zu nutzen und zu betreiben ist. Dieses Modell gewährleistet gleichzeitig eine erstklassige Leistung und Qualität. Diese Methoden werden voraussichtlich in Zukunft in der Branche für Sprachmodelle weit verbreitet sein, da Unternehmen sicher bestrebt sind, kostengünstigere API-Preise anzubieten – wie wir im Folgenden weiter erläutern werden.
So führen Sie DeepSeek-R1 auf Ihrem Computer aus
Da DeepSeek-R1 ein Open-Source-Modell ist, lässt es sich relativ einfach lokal ausführen. Allerdings benötigt Ihr Computer eine hohe Rechenleistung – idealerweise mit einer leistungsfähigen Neural Processing Unit (NPU) oder Graphical Processing Unit (GPU). Falls beides nicht vorhanden ist, läuft das Modell über die CPU, was die Verarbeitung erheblich verlangsamen und die Qualität der Antworten beeinträchtigen kann. Dennoch könnte R1 bessere Ergebnisse liefern als andere Modelle, da es effizient trainiert wurde und mit weniger Ressourcen auskommt.
Schritt 1: Ollama installieren
Um DeepSeek-R1 lokal auszuführen, installieren Sie zunächst Ollama auf Ihrem Computer. Ollama ist ein Open-Source-Tool von Meta, das darauf spezialisiert ist, LLMs einfach und effizient lokal auszuführen. Es dient als eine Art Hub für Open-Source-Sprachmodelle, ähnlich wie GitHub für freie Software. Sobald das Modell gestartet ist, lauscht es auf Port 11434, sodass Sie es für API-Tests oder lokale Integrationen nutzen können.
Schritt 2: Installation je nach Betriebssystem
- Windows & macOS: Laden Sie den Installer von der offiziellen Ollama-Website herunter und folgen Sie den Installationsanweisungen.
- Linux: Führen Sie den folgenden Befehl im Terminal aus curl -fsSL https://ollama.com/install.sh | sh. Wichtig: cURL muss auf Ihrem System installiert sein. Ist dies der Fall, startet die Installation automatisch.
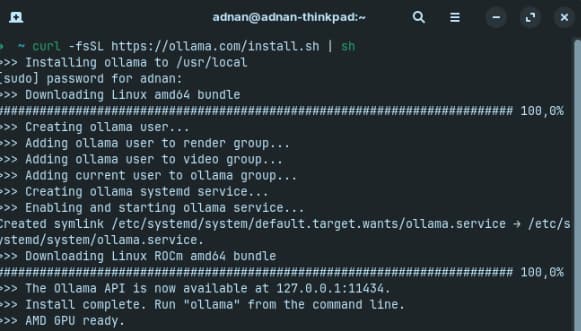
Nun wählen wir auf der DeepSeek-Seite auf der Ollama-Website die gewünschte Modellgröße aus. In diesem Beispiel wählen wir die Version mit 1,5B Parametern, da sie ressourcenschonender ist. Anschließend kopieren wir den Befehl, um das Modell lokal herunterzuladen und auszuführen.
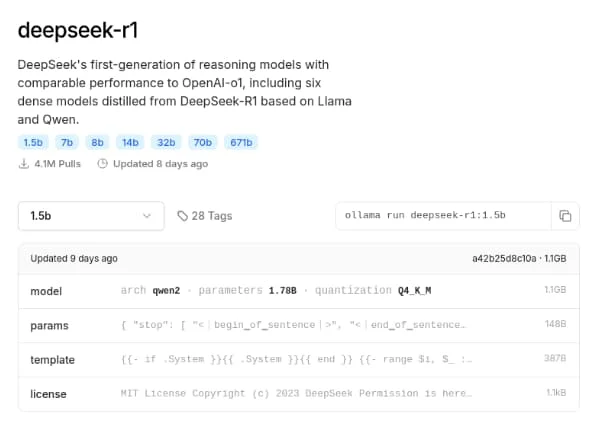
In diesem Fall lautet der Befehl: ollama run deepseek-r1:1.5b.
Nach einer schnellen Installation steht uns DeepSeek zum Chatten bereit. Interessant dabei ist, dass der Denkprozess ersichtlich ist und wir ihn in Echtzeit verfolgen können, bevor die endgültige Antwort ausgegeben wird.
So integrieren Sie DeepSeek-R1 in Ihre API
DeepSeek-R1 lässt sich, wie es in der KI-Branche üblich ist, problemlos mit den Entwicklungstools von OpenAI verbinden. Um von den extrem günstigen Preisen zu profitieren, können Sie also die OpenAI-Bibliotheken verwenden, jedoch mit den URLs von DeepSeek.
Da das Modell zudem Open Source ist, wird häufig die Methode angewendet, es lokal zu verfeinern und über eine Docker-Instanz auf Ihrem Cloud-Provider zu betreiben. So sind Sie nicht direkt von den Servern und Preismodellen von DeepSeek abhängig – stattdessen können Sie es in einer privaten Cloud-Instanz ausführen, was günstiger und sicherer für Ihre Daten ist.
Im Folgenden finden Sie ein kurzes Beispiel für die Integration in eine API-Umgebung. Beachten Sie jedoch, dass Sie in diesem Fall nicht die Entwicklungstools von OpenAI nutzen können, da diese nur mit den offiziellen API-URLs von OpenAI funktionieren.
Hier finden Sie ein schnelles Beispiel zur Integration von DeepSeek-R1 in ein einfaches Node.js und Express Projekt. Dieses Tutorial konzentriert sich ausschließlich auf die KI-Integration – die Erstellung einer neuen Anwendung von Grund auf wird hier nicht behandelt.
- Installieren Sie die OpenAI-Bibliotheken in Ihrer Anwendung
OpenAI hat eine spezielle NPM-Bibliothek entwickelt, um die Integration in Anwendungen zu erleichtern. Sie heißt OpenAI. Um sie in einem Node-Projekt zu installieren, führen Sie folgenden Befehl npm install OpenAI aus:

- Importieren Sie die Bibliothek und erstellen Sie eine Instanz für Ihre Anwendung
Dazu müssen Sie OpenAI aus OpenAI importieren und eine exportierte Instanz der Bibliothek erstellen, wobei die baseUrl auf die DeepSeek-API gesetzt wird, die Ihren apiKey verwendet. Falls Sie noch keinen DeepSeek-API-Schlüssel haben, können Sie hier einen beantragen.
import OpenAI from “openai”;
export const ai = new OpenAI({
baseURL: “https://api.deepseek.com”,
apiKey: process.env.DEEPSEEK_API_KEY,
});
- Passen Sie einen Endpunkt an, um die Eingabeaufforderung „ai“ zu empfangen und die Antwort zu senden
Wie im Screenshot unten zu sehen ist, haben wir einen Beispiel-Router mit einer einzelnen Route namens „example“ eingerichtet. Diese empfängt im Body den Parameter „message“ und leitet ihn an die DeepSeek-API weiter.
import { Router } from “express”;
import { ai } from “../shared/ai”;
const exampleRouter = Router();
exampleRouter.get(“/example”, async (req, res) => {
const { message } = req.body;
if (!message) {
return res.status(400).json({ message: “Message is required” });
}
const response = await ai.chat.completions.create({
messages: [
{
role: “system”,
content: “You are a helpful assistant.”,
},
{
role: “user”,
content: message,
},
],
model: “deepseek-chat”,
stream: false,
})
res.json(response.data.choices[0].message.content);
});
export default exampleRouter;
Hier rufen wir die chat-Eigenschaft im OpenAI-Objekt auf, die selbst eine completions-Eigenschaft und eine create-Methode enthält. Diese create-Methode erstellt eine neue Nachricht für die API und erhält ein Array von Nachrichten, die gesendet werden sollen. Die erste Nachricht enthält normalerweise eine Systemrolle, die definiert, wie sich das LLM verhalten soll und welche Aufgaben es übernehmen muss – die grundlegendste Funktion ist, „ein hilfreicher Assistent zu sein”. Die zweite Nachricht enthält eine Benutzerrolle und übermittelt die Nachricht aus der Anfrage. Anschließend legen wir fest, welches Modell wir verwenden möchten – in diesem Fall deepseek-chat, das Standardmodell der DeepSeek-API – und setzen stream auf false, da wir die Antwort als einen einzelnen Block erhalten möchten.
Dann senden wir die Antwort zurück an den Absender der Anfrage, indem wir response.data.choices[0].message.content verwenden. Obwohl dies eine lange Codezeile ist, handelt es sich um den Standardcode: Da die API einen umfangreichen Denkprozess zurücksendet, so lässt sich die erste generierte Antwort abrufen.
Zur Funktionsweise dieser Modelle: Sie generieren mehrere mögliche Antworten auf die Nutzeranfrage und senden nur diejenigen, die sie für die beste halten. choices[0] wählt die erste Antwort aus dem choices-Array, das diese möglichen Antworten enthält; choices[1] würde die zweitbeste Antwort liefern und so weiter.
Den Code für dieses Beispiel finden Sie hier

Zertifizierte Entwickler
Günstige Stundensätze
Schneller Einstieg
Höchst günstige Bedingungen
Vertrag mit
EU Unternehmen
Deutsch- und englischsprachige Spezialisten
Die Zukunft des KI-Marktes
Wie bereits erwähnt, hat die Veröffentlichung von DeepSeek-R1 den KI-Markt rasant verändert. Sie erschütterte weltweit Aktienkurse und entkräftete den Mythos, dass Unternehmen Milliarden von Dollar für das Training und den Betrieb ihrer Modelle benötigen. Da R1 unter strengen Einschränkungen und mit vergleichsweise wenig Rechenleistung trainiert wurde – sie nutzten sogar GPUs von Huawei –, was lange als unbestreitbare Wahrheit galt, ist jetzt höchst unsicher.
Nun ist es klar geworden, dass der Markt einen massiven Wandel erlebt hat und nicht mehr zum alten Zustand zurückkehren wird. Die Auswirkungen waren so groß, dass OpenAI bereits ein neues, kosteneffizientes Modell namens o3-mini angekündigt hat, das als direkte Konkurrenz zu R1 entwickelt wurde. Auch der chinesische Technologiekonzern Alibaba hat mit Qwen2.5-Max ein neues Modell veröffentlicht. Es ist offensichtlich, dass der Wettbewerb um das beste KI-Modell neu begonnen hat – und dies verleiht dem Markt neuen Schwung.
Doch ein neuer großer Player bleibt eine Unbekannte – Nvidia. Nach der Veröffentlichung von R1 fiel der Aktienkurs des Unternehmens um 15 %, und es ist ungewiss, welche Rolle seine hochpreisigen GPUs und TPUs in Zukunft spielen werden. Klar ist, dass Nvidias frühere Marktdominanz nicht mehr so stabil ist, wie viele dachten. Zudem ist nun bewiesen, dass leistungsstarke LLMs auch ohne ihre Hardware entwickelt werden können. Nvidia profitierte bisher davon, die „Spitzhacken“ an die Goldgräber des KI-Booms zu verkaufen – jetzt wird sich zeigen, wie der Markt auf diese neue Realität reagiert.
Fazit
Unter dem Strich profitieren vor allem die Nutzer und Entwickler, die jetzt Zugang zu erstklassigen Technologien haben und bessere Lösungen günstig bekommen. Wie bereits erwähnt, haben KI-APIs die Gewinnmargen vieler SaaS-Unternehmen um bis zu ein Drittel gesenkt, da sie immer häufiger verwendet und für zahlreiche Produkte unverzichtbar wurden. Mit diesen neuen Entwicklungen können Unternehmen ihre Margen stabil halten, während Qualität und Geschwindigkeit weiter steigen. Außerdem werden neue, effizientere KI-Modelle immer energieeffizienter, wodurch die Umweltbelastung durch CO₂-Emissionen und Wasserverbrauch sinkt.
Sollte Ihre Anwendung noch nicht von den Vorteilen von DeepSeek-R1 profitieren, kontaktieren Sie uns bei Chudovo. Wir helfen Ihnen dabei, die modernsten KI-Technologien in Ihre App zu integrieren. So maximieren Sie das Potenzial Ihres Unternehmens und optimieren Ihre Prozesse – unabhängig von Ihren spezifischen Anforderungen. Nutzen Sie diese neue Ära der künstlichen Intelligenz und lassen Sie uns gemeinsam Ihre Anwendung auf das nächste Level bringen!