Was sind KI-Agenten: Einsatz und Erstellung
Ein KI-Agent ist eine Anwendung, die ein oder mehrere KI-Sprachmodelle integriert und eine Reihe von Parametern nutzt, um ein bestimmtes Ziel zu erreichen. Wie gut ein KI-Agent funktioniert, hängt davon ab, welches Modell eingesetzt wird und welche Funktionen der Entwickler vorgesehen hat. Das ermöglicht eine besonders individuelle Anwendung von Sprachmodellen: Man kann auch kleinere Sprachmodelle einsetzen, die genauso präzise Ergebnisse liefern. Dadurch werden auch die Kosten erheblich gespart.
Was einen gut entwickelten KI-Agenten grundlegend von der einfachen API-Nutzung wie bei ChatGPT unterscheidet, ist die Spezialisierung und Effizienz: APIs sind oft teurer und weniger individuell zugeschnitten. Ein maßgeschneiderter KI-Agent liefert bessere Ergebnisse, da er perfekt auf das Projekt abgestimmt ist. Gleichzeitig spart man Geld, da kleinere Sprachmodelle (Small Language Models, kurz SLMs) verwendet werden können. Diese lassen sich lokal mit frei verfügbaren Ollama-Modellen betreiben oder über besonders günstige Online-APIs nutzen.
Daher gelten KI Agenten inzwischen als die effizienteste Art, künstliche Intelligenz einzusetzen, und daher werden sie immer häufiger im Markt eingesetzt. Hier erfahren Sie alles, was Sie wissen müssen!
Was genau ist ein KI-Agent?
Zunächst sollten wir genauer betrachten, was ein „Agent“ überhaupt ist. Es handelt sich dabei um ein System – genauer gesagt um eine Art Server -, das KI integriert, um Anfragen entgegenzunehmen, sie zu verarbeiten und entsprechende Antworten zu liefern. Der größte Unterschied liegt darin, dass der Agent sich frühere Eingaben merkt (Stichwort: Kontext-Spanne) und dadurch seine zukünftigen Antworten verbessern kann. Dafür wird das Sprachmodell mit Anweisungen vorkonfiguriert: Damit ist klar, wie Eingaben zu interpretieren sind, welche Arten von Informationen erwartet werden und welches Ergebnis erzielt werden soll. Zudem kann der Agent über seine Speichermechanismen sogar während der Laufzeit angepasst werden – auch wenn das eher nicht empfohlen wird – dazu später mehr.
Da KI-Agenten in der Regel lokal oder auf einem privaten Server laufen und stark spezialisiert sind, lassen sich dafür hervorragend Small Language Models verwenden. Diese haben weniger Parameter als große Modelle (LLMs) und sind deutlich ressourcenschonender. Damit spart man viel Geld bei der Verarbeitung und profitiert von einem effizienteren Einsatz in der Praxis, da kleinere Modelle auch eine kürzere Kontextspanne haben. Außerdem lassen sich mehrere SLMs kombinieren, um ein breiteres Anwendungsspektrum abzudecken – ohne eigene Infrastruktur stark zu belasten.
Darüber hinaus bieten KI-Agenten durch sogenannte Bewertungsschichten im Verarbeitungsprozess eine deutlich höhere Genauigkeit. Das bedeutet: Ein Modell generiert eine Antwort und überprüft sie anschließend noch einmal, um die Qualität der Antwort zu validieren. Ist die Antwort nicht zufriedenstellend, wird ein neuer Versuch gestartet. Solche Agenten passen ihr Verhalten basierend auf Feedback und gespeicherten Informationen an – und genau deshalb sind sie so leistungsstark.
Aus diesen Gründen sind KI-Agenten aktuell die innovativste und effektivste Methode im KI-Breich. Der Unterschied zwischen einem einfachen API-Aufruf bei OpenAI und der Anfrage an einen hochspezialisierten KI-Agent ist enorm – und genau deshalb ist es so wichtig, sich heute mit dieser Technik auseinanderzusetzen.
Grundlegende Architektur eines KI-Agenten
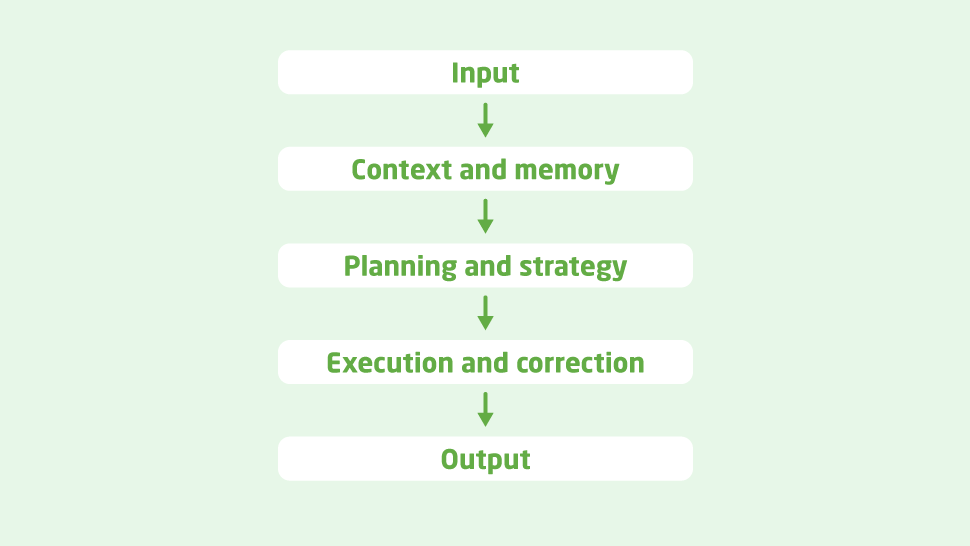
Um das praktisch greifbar zu machen, schauen wir uns den tatsächlichen Aufbau einer solchen Anwendung an. Zunächst betrachten wir die Architektur eines einfachen Agenten und sehen uns anschließend an, wie man ihn implementieren kann. Grundsätzlich besteht er aus mehreren Schichten, die wir nun näher betrachten:
- Eingabe. Dies ist der einfachste Teil der Architektur. Die Anfrage eines Nutzers gelangt über die Eingabeschicht ins System. Diese Eingabe kann auf unterschiedliche Weise erfolgen – etwa über einen direkten API-Aufruf an den Server oder über eine benutzerfreundliche Oberfläche mit Chat-Funktion, die das Ganze abstrahiert.
- Kontext und Speicher. In dieser Schicht lernt der Agent zu verstehen, was gerade passiert, um das Sprachmodell gezielt auf Sie zuzuschneiden. Er erfasst den Kontext Ihrer Anfrage sowie der gesamten Anwendung. Dabei wird auch das bereits Geschehene – also die gespeicherten ‚Erinnerungen‘ – einbezogen, um die Daten sinnvoll zu verarbeiten.
- Planung und Strategie. Diese Schicht teilt den Prozess in Schritte auf und legt fest, wie sie umgesetzt werden sollen. Der Agent kann die Aufgabe in Teilе zerlegen, um sie effizienter zu lösen. In anderen Fällen kann er eine Eingabe aufteilen und verschiedene Modelle nutzen – z. B. den Textanteil analysieren lassen und einen anderen Teil zur Bildgenerierung an ein anderes Modell weitergeben.
- Ausführung und Korrektur. Nun wird der zuvor erstellte Plan umgesetzt, um die Informationen zu verarbeiten und eine Antwort zu liefern. Die Korrektur-Schicht sorgt dafür, dass der Plan auch tatsächlich eingehalten und korrekt angewendet wurde. Wird ein Fehler erkannt, wird der Prozess neu gestartet, bis ein zufriedenstellendes Ergebnis erreicht ist. So wird das Risiko für sogenannte „Halluzinationen“ drastisch reduziert und die Qualität der Antwort erheblich gesteigert – der Agent liefert genau das, was Sie erwarten.
- Ausgabe. Diese Schicht ist dafür zuständig, die generierte Antwort so aufzubereiten, dass sie für den Endnutzer klar und intuitiv bedienbar ist.
Das lässt sich in diesem Diagramm zusammenfassen:
Einfache Implementierung eines KI-Agenten mit Python
Jetzt schauen wir uns an, wie man einen KI-Agenten implementiert. Dafür verwenden wir Python – die am häufigsten genutzte Programmiersprache im Bereich der künstlichen Intelligenz. Hier sehen Sie den grundlegenden Aufbau des Projektordners:
agent/
├── agent.py
├── memory.py
├── planner.py
├── evaluator.py
├── preferences.py
├── llm.py
└── main.py- memory.py: Dieser Code erstellt einen einfachen Speicherblock auf Basis eines Arrays – das ist zwar leicht verständlich, aber nicht die effizienteste Methode. Außerdem sind einige Methoden implementiert, wie etwa get_recent, die die fünf letzten Speicherblöcke zurückgibt, sowie clear, die den Verlauf löscht.
# memory.py
class Memory:
def __init__(self):
self.history = []
def add(self, message: str, role: str = "user"):
self.history.append({"role": role, "content": message})
def get_recent(self, n=5):
return self.history[-n:]
def clear(self):
self.history = []- preferences.py: Es verwendet ein Preset, um die Präferenzen des Nutzers zu übernehmen, sodass man sie nicht immer wieder im Code konfigurieren muss. Der Zweck dahinter orientiert sich hauptsächlich am Don’t-Repeat-Yourself-Prinzip.
# preferences.py
class UserPreferences:
def __init__(self, style="formal", language="en", verbosity="medium"):
self.style = style
self.language = language
self.verbosity = verbosity
def to_prompt_instruction(self):
return f"Respond in a {self.style} style, in {self.language}, with {self.verbosity} verbosity."- planner.py: Implementiert die Logik, um je nach Aufforderung verschiedene Pläne zu erstellen. Dieser ist sehr einfach, kann aber so weit variieren, dass er in verschiedene Sprachmodelle abweicht, wie zum Beispiel das Erzeugen eines Bildes oder Videos anstelle von Text. Es kann dann das umsetzen, was wir als multimodalen Agenten wahrnehmen. Es kann auch Aufforderungen erkennen, die sich häufig wiederholen, wie zum Beispiel „Danke“, und standardisierte Antworten liefern.
# planner.py
class Planner:
def create_plan(self, user_input: str):
if "summary" in user_input.lower():
return ["Extract key ideas", "Write summarized paragraphs"]
elif "code" in user_input.lower():
return ["Analyze requirements", "Write code", "Test and verify"]
else:
return ["Understand request", "Generate direct response"]- evaluator.py: Erstellt die Grenze, um die Antwort zu validieren. In diesem Beispiel wird nur geprüft, ob die Antwort des Sprachmodells zu lang oder zu kurz ist.
# evaluator.py
class Evaluator:
def evaluate(self, output: str):
# Example of basic heuristics (could also call an LLM for deeper critique)
if "error" in output.lower():
return "Needs correction"
elif len(output) < 20:
return "Too short"
return "Acceptable"- llm.py: Das ist die Schicht, die die Eingabe effektiv im Sprachmodell ausführt. In diesem Beispiel wird die OpenAI-API und die Python-Bibliothek verwendet.
# llm.py
import openai
class LLM:
def __init__(self, model="gpt-4"):
self.model = model
def ask(self, messages):
response = openai.ChatCompletion.create(
model=self.model,
messages=messages,
temperature=0.7,
max_tokens=512
)
return response.choices[0].message["content"]- agent.py: Diese Datei fasst im Grunde alles in einer einzigen Klasse zusammen, damit alles reibungslos funktioniert.
# agent.py
from memory import Memory
from preferences import UserPreferences
from planner import Planner
from evaluator import Evaluator
from llm import LLM
class IntelligentAgent:
def __init__(self):
self.memory = Memory()
self.preferences = UserPreferences()
self.planner = Planner()
self.evaluator = Evaluator()
self.llm = LLM()
def handle_input(self, user_input: str):
self.memory.add(user_input, role="user")
plan = self.planner.create_plan(user_input)
instruction = self.preferences.to_prompt_instruction()
context = self.memory.get_recent()
messages = [{"role": "system", "content": instruction}]
messages += context
messages.append({"role": "user", "content": f"Plan: {plan}\n{user_input}"})
response = self.llm.ask(messages)
evaluation = self.evaluator.evaluate(response)
self.memory.add(response, role="assistant")
print("🔄 Response evaluation:", evaluation)
return response- main.py: Diese Datei enthält die Klasse, die die gesamte Funktionalität umsetzt. Sie stellt die einfachste Möglichkeit dar, den Agenten zu implementieren – direkt im Terminal mit Benutzereingaben. Öfter erfolgt aber die Umsetzung über eine REST-API, beispielsweise mit den Python-Frameworks FastAPI oder Flask.
# main.py
from agent import IntelligentAgent
if __name__ == "__main__":
agent = IntelligentAgent()
while True:
user_input = input("👤 You: ")
if user_input.lower() in ["exit", "quit"]:
break
output = agent.handle_input(user_input)
print("🤖 Agent:", output)Fine-Tuning vs. Prompt Engineering: Was wäre besser für Sie?
Ein weiterer und sehr wichtiger Anwendungsfall für ein KI-Modell ist das Fine-Tuning – also die Anpassung an individuelle Bedürfnisse. Deshalb ist es wichtig, den Unterschied zwischen dem Fine-Tuning-Prozess und der reinen Optimierung der Prompts für das verwendete Sprachmodell zu erklären.
Beim Fine-Tuning wird das Modell teilweise neu trainiert – und zwar mit Ihren eigenen Daten. Es handelt sich um eine gezielte Modifikation des Modells, um es besser an Ihre Anforderungen und Anwendungsbereich anzupassen. Wenn Sie Fine-Tuning einsetzen wollen, sollten Sie Folgendes berücksichtigen: Fine-Tuning ist extrem rechenintensiv und mit entsprechenden Kosten verbunden. Außerdem ist der Prozess relativ komplex, und Sie benötigen dafür vor allem eine große Menge gut strukturierter, qualitativ hochwertiger Daten. In den meisten Fällen lohnt sich dieser Aufwand daher nicht.
In solchen Fällen ist Prompt Engineering eine bessere Wahl. Darunter versteht man bewährte Methoden und Techniken, um durch eine gezielte Formulierung des Prompts optimale Ergebnisse zu erzielen. Es handelt sich um eine ganz präzise Beschreibung Ihrer Anfrage, die Definition der gewünschten Rolle des Sprachmodells oder die klare Angabe der erwarteten Antwort. Zusätzlich lassen sich auch bestimmte Parameter im Prompt übergeben, zum Beispiel:
- Temperature (Wert zwischen 0 und 1): Gibt an, wie zufällig bzw. kreativ die Ergebnisse sein sollen
- max_tokens: Maximale Länge der Antwort in Token
- presence_penalty und frequency_penalty (jeweils von -2 bis 2): Steuern, ob und wie stark Wiederholungen vermieden oder zugelassen werden
Mit all diesen Einstellungen lässt sich sehr genau angeben, was Sie vom Sprachmodell erwarten – und somit können Sie dessen Potenzial ausnutzen.
Fazit
Unter dem Strich ist der Aufbau eigener Agenten eine der effizientesten Möglichkeiten, von den aktuellen Entwicklungen im KI-Bereich zu profitieren. Es ist günstiger, robuster und besser auf Ihre individuellen Bedürfnisse abgestimmt. Zweitens, vermeiden Sie damit hohe laufende Kosten für Modelle wie ChatGPT oder Claude. Außerdem läuft der Agent auf Ihrer eigenen Maschine oder einem Server, den Sie kontrollieren – Ihre Daten bleiben also bei Ihnen, ohne externes Tracking, komplett in Ihrer Hand.
Da Sie den Agenten selbst entwickeln lassen, können Sie ihn kontinuierlich verbessern: mehr Speicher, längere Kontexte, zusätzliche Funktionalität – ganz wie Sie es brauchen. Im Grunde genommen gehört Ihnen der gesamte Code, und Sie können daraus machen, was immer Sie möchten. Beispielsweise könnten Sie den Agenten zu einem multimodalen System weiterentwickeln: Bilder generieren, verschiedene Eingabeformate verarbeiten und vieles mehr. Die Möglichkeiten sind unbegrenzt – nur Sie bestimmen, wie weit es gehen soll.
Wenn Sie einen modernen KI-Agenten brauchen, der optimal auf Ihre Bedürfnisse zugeschnitten ist, dann kontaktieren Sie uns bei Chudovo. Wir sind ein Beratungsunternehmen, das hochwertige Softwarelösungen in verschiedenen Bereichen realisiert – darunter viele komplexe KI und ML Projekte. Vereinbaren Sie einen Termin mit uns, um herauszufinden, wie Ihre Geschäftsprozesse durch maßgeschneiderte Automatisierungslösungen optimiert, skaliert und kosteneffizient weiterentwickelt werden können.