COBOL zu Kubernetes Migration: Ein praktischer Architekturleitfaden zur Modernisierung von z/OS-Anwendungen
COBOL auf z/OS wurde nicht für Migration entwickelt. Es wurde dafür geschaffen, korrekt, schnell und langfristig stabil zu funktionieren. Systeme, die seit über 30 Jahren im Einsatz sind, bestehen weiterhin, weil sie stabil funktionieren. Genau diese Stabilität macht ihre Modernisierung jedoch besonders anspruchsvoll.
Viele Mainframe-Modernisierungsprojekte überschreiten ihr Budget noch bevor der vollständige Projektumfang realisiert wurde. In den meisten Fällen liegt dies an denselben wiederkehrenden Problemen.
Ganz gleich, ob Sie bereits mit einer solchen Situation konfrontiert waren oder diese vermeiden möchten, dieser Leitfaden umfasst genau die Aspekte, die in solchen Projekten entscheidend sind. Im Folgenden zeigen wir einen praxisnahen Architekturansatz für die Migration von COBOL-Workloads zu Kubernetes. Der Schwerpunkt liegt darin, die Legacy-Modernisierung ohne vollständige Neuentwicklung umzusetzen und gleichzeitig Systeme aufrechtzuerhalten, die täglich Millionen von Transaktionen verarbeiten.
Warum die Migration vom Mainframe zu Kubernetes häufig scheitert
Solche Misserfolge haben meist klare Ursachen. In der Regel lassen sie sich auf drei typische Muster zurückführen, wobei zwei davon bereits auf frühe Architekturentscheidungen im Projekt zurückgehen.
Schauen wir uns das häufigste Problem an: der Falle der vollständigen Neuentwicklung.
Der Ablauf sieht meist folgendermaßen aus:
- Jemand bewertet den Umfang der COBOL-Codebasis
- Der Aufwand wird anhand eines Umrechnungsfaktors kalkuliert
- Anschließend wird vorgeschlagen, alles vollständig in Go oder Java neu zu entwickeln
Irgendwann erreicht die neue Anwendung die Produktionsumgebung, und plötzlich treten Sonderfälle auf, die niemand berücksichtigt hat. Dabei handelt es sich häufig um geschäftskritische Sonderlogiken, die durch Patches aus den 1980er-Jahren gelöst wurden und bei der Migration nicht übernommen wurden.
Das zentrale Problem einer vollständigen Neuentwicklung besteht darin, dass alte Geschäftslogik häufig unterschätzt oder übersehen wird. COBOL-Anwendungen funktionieren oft auf eine Weise korrekt, die nie vollständig dokumentiert wurde, weil die tatsächliche Funktionsweise des Systems über viele Jahre hinweg oft wichtiger geworden ist als jede formale Dokumentation.
Der Lift-and-Shift-Fehler funktioniert genau umgekehrt. Jemand sagt: „Wir packen das kompilierte COBOL einfach in einen Container“ und nennt das dann „modernisiert“. Auf der Laufzeitebene ändert sich aber nichts. Die Realität ist: Es entsteht zusätzlicher Kubernetes-Betriebsaufwand, während das System weiterhin von z/OS-Semantiken abhängig bleibt.
Schließlich ist auch das zu aggressiv angewendete Strangler-Pattern problematisch, wenn auch subtiler. Dies passiert, wenn Teams eine Komponente herauslösen, einen Microservice erstellen und den Erfolg verkünden, ohne gemeinsam genutzte Transaktionszustände, den DB2-Cursor-Scope oder die Sequenzierung von MQ-Nachrichten zu berücksichtigen. Der extrahierte Service funktioniert isoliert. Unter Last bricht er jedoch zusammen, sobald er mit den Systemen interagiert, die er eigentlich ersetzen sollte.
Wie man Mainframe-Anwendungen in die Cloud migriert, ohne sie neu zu schreiben
Wir sind überzeugt, dass der Großteil der heute produktiv eingesetzten COBOL-Codebasen seit mehr als zehn Jahren besteht. Ebenso wird deutlich, dass jede dieser Codebasen Elemente enthält, die aus früheren Entwicklungsphasen stammen und heute niemand mehr vollständig nachvollziehen kann: Logik zur Datumsverarbeitung, die das Y2K-Problem aus spezifischen Gründen überstanden hat, sowie Transaktions-Rollback-Sequenzen, die korrekt funktionieren, weil sie anhand realer Fehlerfälle validiert wurden.
Im vorherigen Abschnitt haben wir die Risiken einer vollständigen Neuentwicklung definiert. Teams, die diesen Realitätscheck überspringen, verbringen etwa 18 Monate mit der Neuentwicklung und weitere 18 Monate mit der Behebung von Regressionen.
Nun geht es darum, wie die Migration sinnvoll umgesetzt werden kann. Erfahrung von Chudovo zeigt, dass eine schrittweise Refaktorisierung von COBOL-Monolithen das verifizierte Produktionsverhalten unverändert lässt und gleichzeitig ermöglicht, einzelne Anwendungsteile gezielt zu testen, kritische Probleme frühzeitig zu erkennen und bei Misserfolg ein schnelles und sicheres Rollback sicherzustellen.
Betrachten Sie das bestehende COBOL-System als die detaillierteste Spezifikation, die Ihnen zur Verfügung steht. Ihre Aufgabe besteht darin, dieses System in einzelne, deploybare Einheiten zu zerlegen. Nicht darin, den beschriebenen Ablauf zu ersetzen.
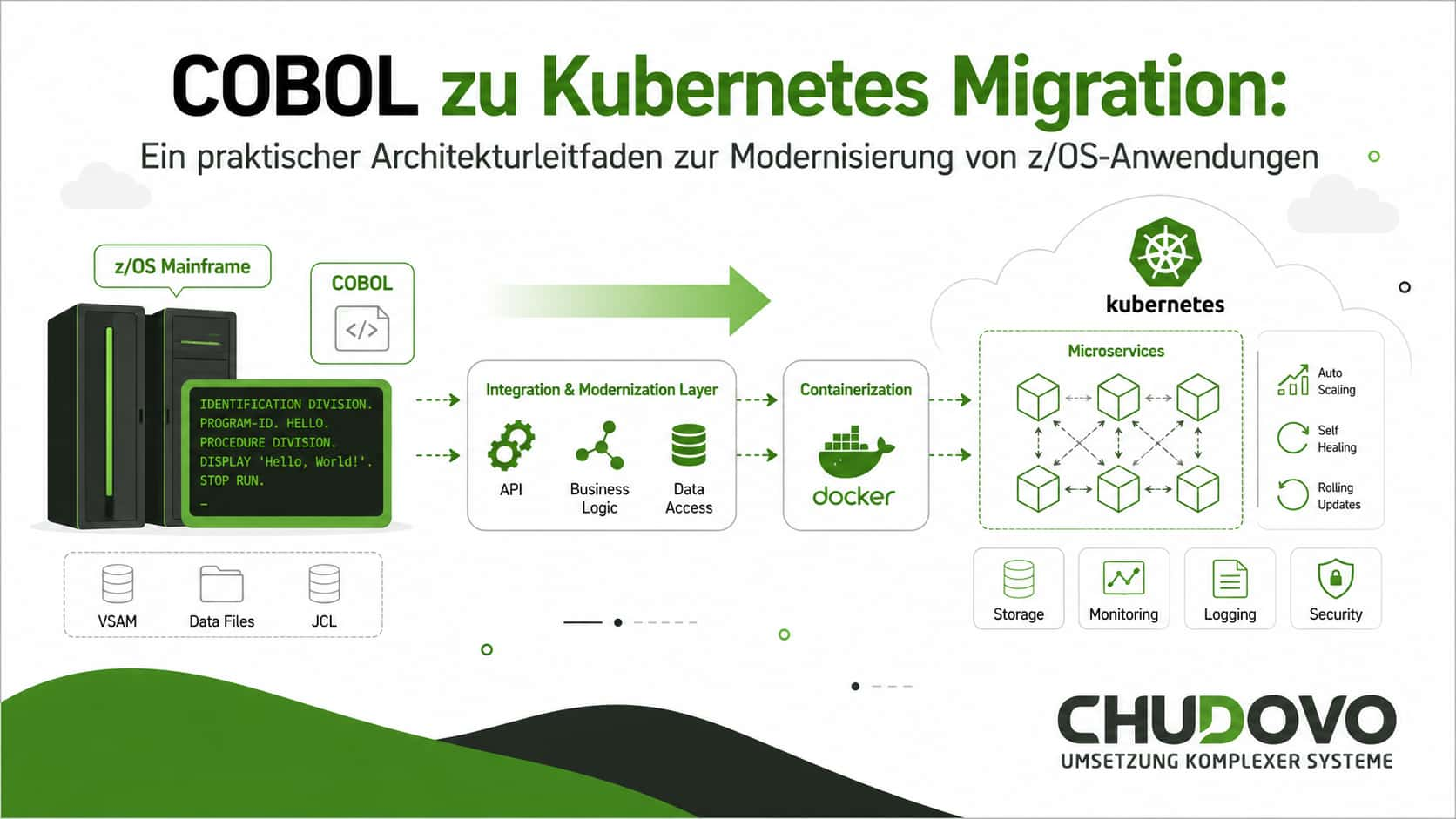
Inkrementelle Strategie zur COBOL-Cloud-Migration mit dem Strangler-Pattern
Das Strangler-Pattern ist eine Migrationsstrategie, bei der neue Funktionalitäten schrittweise alte Systeme ersetzen, ohne einen vollständigen Umstellungsprozess („Big Bang“) zu erfordern. Der Begriff stammt vom Feigenbaum, der einen Wirt umwächst. In der Tat sieht es so aus: Das gesamte System wird nicht auf einmal migriert. Stattdessen identifiziert man eine klar abgegrenzte Funktion, leitet den Datenverkehr auf eine neue Implementierung um, validiert diese und stellt den alten Pfad anschließend schrittweise ein.
Im Kontext der Mainframe-Migration stellt dieses Muster ein geeignetes Vorgehensmodell dar, um COBOL-Anwendungen nach Kubernetes zu überführen. Der Ansatz ist relativ einfach: Sie fügen eine API-Schicht vor das bestehende z/OS-System hinzu und der Datenverkehr wird nach und nach auf containerisierte Services umgeleitet, sobald diese validiert sind. Das ursprüngliche z/OS-System bekommt dabei immer weniger Last, bis es schließlich vollständig außer Betrieb genommen werden kann. Während der gesamten Migration bleibt der Mainframe als Fallback-Option verfügbar.
Dieser Abschnitt dient als praktisches Beispiel für die Anwendung des Strangler-Patterns im Mainframe-Umfeld.
Den Monolithen über APIs zugänglich machen (API-Enablement)
Der erste Schritt, bevor der Datenverkehr von CICS weggeleitet wird, besteht darin, eine klare Schnittstelle zu schaffen: eine API-Gateway-Schicht, die auf einer verteilten Plattform bereitgestellt wird. Diese nimmt eingehende Anfragen entgegen und leitet sie an das z/OS-Backend weiter. An den COBOL-Programmen selbst ändert sich in dieser Phase noch nichts. Dieser Schritt dient dazu, das System zu instrumentieren und die notwendige Transparenz über den Datenverkehr zu schaffen, die später benötigt wird. IBM z/OS Connect ist hier eine mögliche Lösung; je nach eingesetzter CICS-Version kommen auch andere Optionen infrage.
Geeignete Komponenten für die Zerlegung wählen
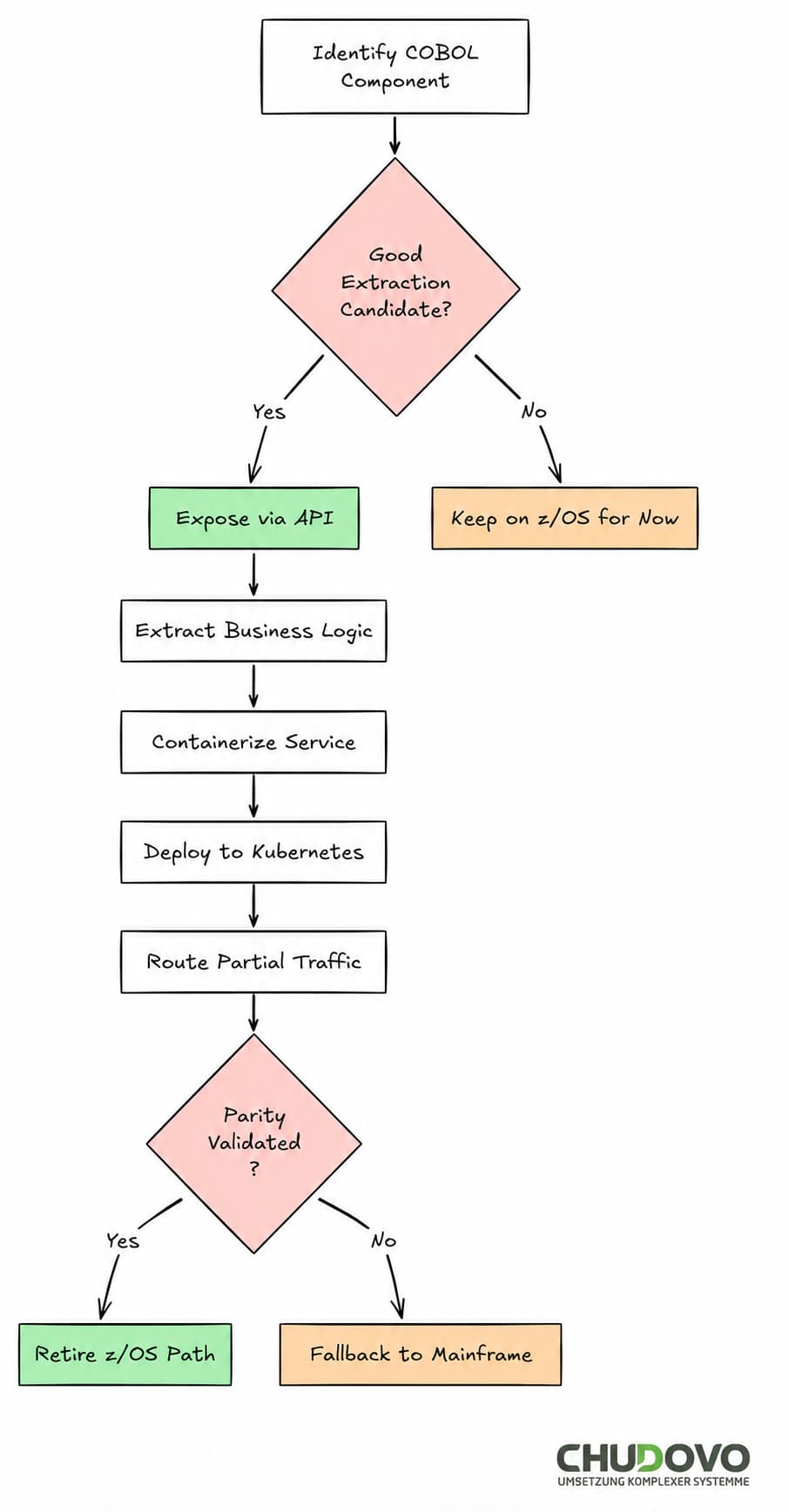
Nicht alle COBOL-Programme eignen sich für eine Extraktion. Gute Komponenten weisen typischerweise folgende Eigenschaften auf:
- klare Input- und Output-Schnittstellen ohne gemeinsame VSAM-Abhängigkeiten
- Batch-Jobs ohne Abhängigkeit vom Echtzeit-CICS-Zustand
- Lookup- oder Validierungslogik ohne schreibende Seiteneffekte
Weniger geeignet sind stark gekoppelte Komponenten, die auf DB2-Unit-of-Work-Scope, CICS-Commarea-State oder JES2-Job-Abhängigkeiten angewiesen sind, die sich außerhalb des Mainframes nur schwer nachbilden lassen.
Extraktion und Containerisierung
Sobald eine geeignete Komponente festgelegt wurde, folgt die Extraktion der Geschäftslogik in einen eigenständigen Service. Das Engineering-Team von Chudovo nutzt dabei ein Vorgehensmodell, bei dem COBOL-Quellcode zunächst in Java überführt wird (unter Einsatz von Tools wie Micro Focus Enterprise Developer oder IBM Application Discovery) und anschließend von z/OS-spezifischen Laufzeitabhängigkeiten bereinigt wird. Der entstandene Service wird containerisiert und in Kubernetes bereitgestellt.
Routing und Validierung
Für diesen Schritt empfiehlt sich eine schrittweise Verkehrsaufteilung. Das API-Gateway leitet einen Teil der Anfragen an den neuen Container-Service weiter. Die Antworten beider Systeme werden in Echtzeit miteinander verglichen. Dieser sogenannte Dark-Launch-Ansatz stellt sicher, dass Vertrauen in den neuen Service aufgebaut wird, bevor er die vollständige Produktionslast trägt.
Ablösung des z/OS-Pfads
Sobald der containerisierte Service eine gleichwertige Funktionalität nachweist, wird der Datenverkehr vollständig umgestellt. Der COBOL-Teil wird anschließend aus CICS außer Betrieb genommen.
Können COBOL-Anwendungen in Containern ausgeführt werden?
Mit Tools wie Micro Focus COBOL for JVM oder GnuCOBOL ist es grundsätzlich möglich, bestehende Mainframe-Workloads zu containerisieren.
Ob dieser Ansatz sinnvoll ist, hängt jedoch stark davon ab, welches Ziel verfolgt wird. Die Ausführung kompilierter COBOL-Anwendungen in Containern schafft vor allem mehr Flexibilität bei der Bereitstellung. Was dadurch trotzdem nicht automatisch entsteht, sind horizontale Skalierbarkeit, API-First-Architekturen oder unabhängig deploybare Services. Im Kern handelt es sich weiterhin um einen Monolithen innerhalb eines Pods.
Für kleinere, gut isolierte Programme, beispielsweise Hilfsfunktionen für Berechnungen oder Routinen zur Datumskonvertierung, kann dieser Ansatz pragmatisch und effizient sein.
Bei geschäftskritischen Transaktionsprogrammen, die eng mit CICS-Zuständen und DB2-Cursor-Management verknüpft sind, bleibt eine tiefere Refaktorisierung jedoch unabhängig von der gewählten Laufzeitumgebung notwendig.
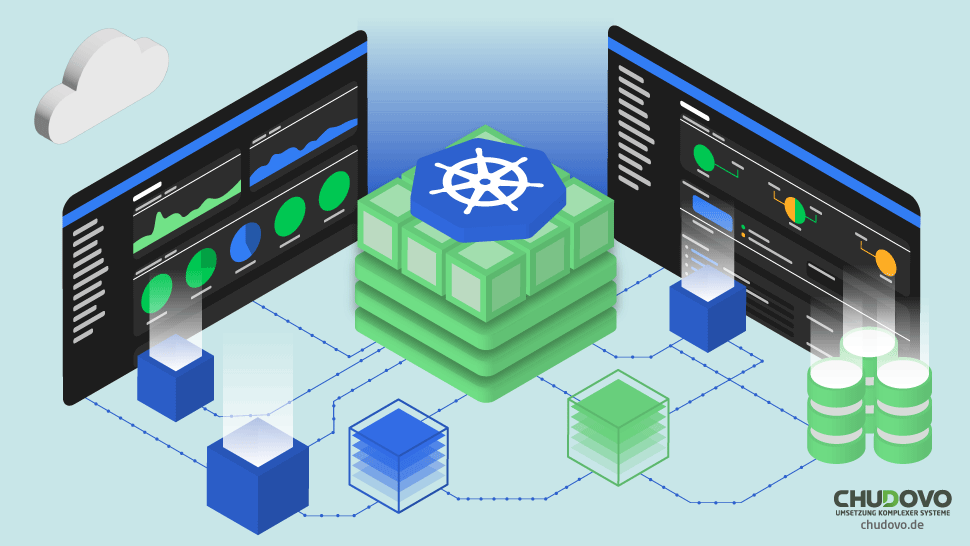
Mainframe-Modernisierungsarchitektur für z/OS in der Praxis
Eine Architektur für die Migration von z/OS in die Cloud basiert typischerweise auf folgendem Architekturmodell:
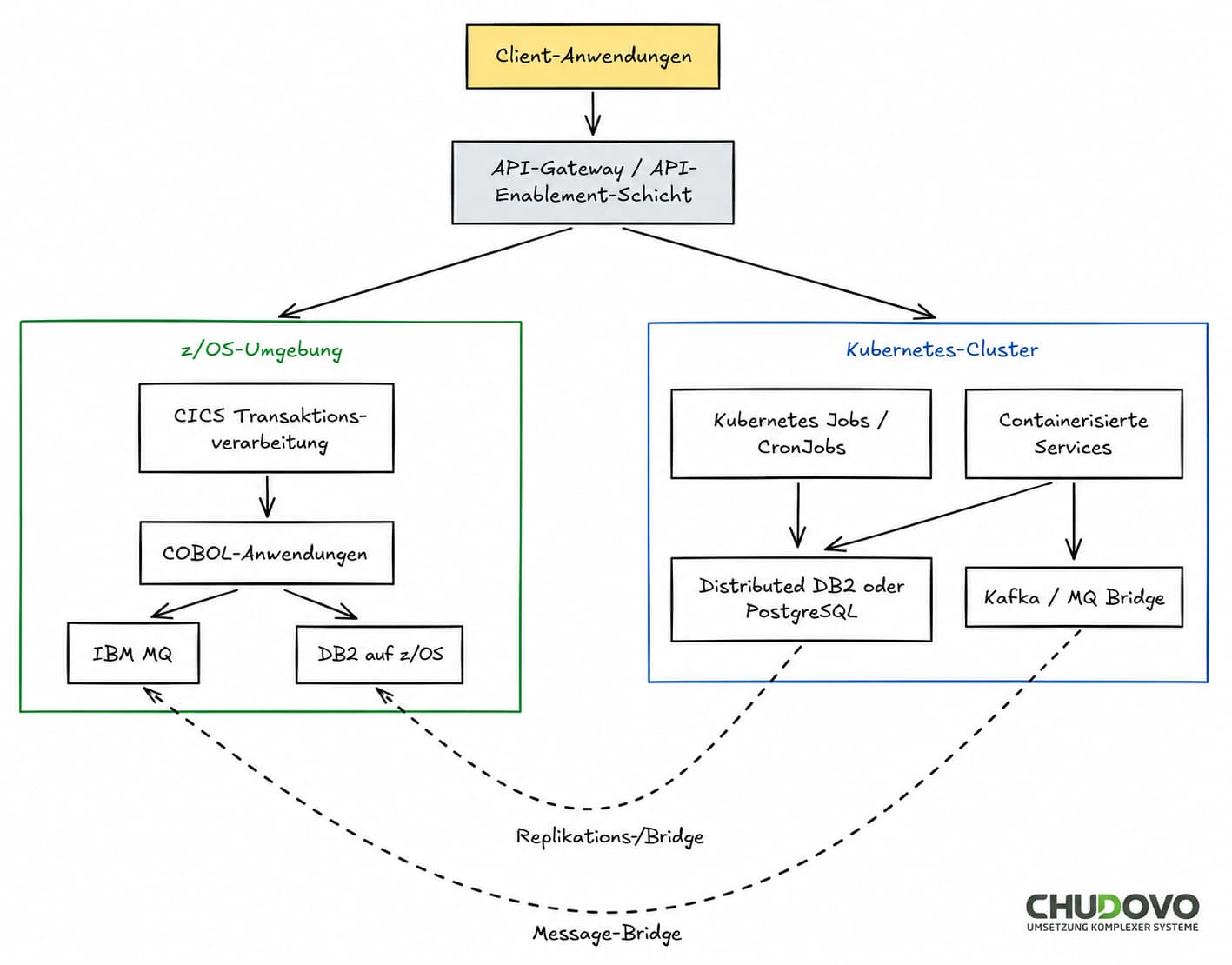
In den meisten z/OS-Modernisierungsprojekten ist DB2 der letzte Bestandteil, der migriert wird. Das Risiko einer DB2-Datenmigration, während COBOL-Programme weiterhin aktiv sind, ist erheblich. Ein häufig genutzter Zwischenzustand besteht in einer DB2-Bridge: Containerisierte Services schreiben in eine verteilte DB2-Instanz, die ihre Daten mithilfe von IBMs eigener Replikationstechnologie mit z/OS DB2 synchronisiert. Im Laufe der Zeit wird z/OS DB2 in einen Read-Only-Zustand überführt und anschließend komplett außer Betrieb genommen.
Bereitstellungen in Kubernetes orientieren sich dabei typischerweise an Architekturmustern wie dem folgenden.
apiVersion: apps/v1
kind: Deployment
metadata:
name: account-service
spec:
replicas: 3
selector:
matchLabels:
app: account-service
template:
metadata:
labels:
app: account-service
spec:
containers:
- name: account-service
image: account-service:latest
ports:
- containerPort: 8080So sieht der Zielzustand einer gemischten z/OS- und Kubernetes-Umgebung während einer laufenden Migration typischerweise aus:
| Ebene | z/OS (Legacy) | Kubernetes (Zielumgebung) |
| Transaktionsverarbeitung | CICS | Containerbasierte REST- oder gRPC-Services |
| Batch-Verarbeitung | JES2 / JCL | Kubernetes Jobs oder CronJobs |
| Datenspeicherung | VSAM, DB2 auf z/OS | Verteiltes DB2 oder PostgreSQL |
| Messaging | IBM MQ | Message-Queue-Bridge über Kafka oder MQ |
| Integration | COBOL-Subroutinen | Interne APIs |
Von CICS zu COBOL-Microservices: Ein Architekturbeispiel für die Migration von COBOL zu Microservices
Betrachten wir eine Abfrage des Kundenkontostands. Auf z/OS sieht dieser Prozess typischerweise als CICS-Transaktionsablauf aus: Ein Kunde sendet eine Anfrage, CICS leitet diese an ein COBOL-Programm weiter, das Programm führt eine DB2-SELECT-Abfrage aus, die Antwort wird im COMMAREA-Format aufbereitet und anschließend wird das Ergebnis zurückgegeben. Die gesamte Verarbeitung dauert in der Regel zwischen 8 und 20 Millisekunden.
Wie wird ein solcher Prozess in einen containerisierten Service migriert?
In der Praxis überführt das Team von Chudovo diese Logik meist nach Java, entfernt den EXEC CICS RETURN-Befehl, ersetzt den EXEC SQL-Block durch JDBC und integriert die Geschäftslogik in einen Spring-Boot-REST-Controller. Anschließend wird beispielsweise ein Endpoint wie GET /accounts/{id}/balance bereitgestellt, wodurch Kubernetes Routing, Skalierung und Container-Orchestrierung steuert.
Die grundlegende Geschäftslogik bleibt dabei unverändert. Was sich vollständig verändert, ist die Laufzeitumgebung.
Ein vereinfachtes Beispiel für die ursprüngliche COBOL-Struktur könnte wie folgt aussehen:
IDENTIFICATION DIVISION.
PROGRAM-ID. BALQRY.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 WS-ACCOUNT-ID PIC X(12).
01 WS-BALANCE PIC S9(13)V99 COMP-3.
01 WS-SQLCODE PIC S9(9) COMP.
LINKAGE SECTION.
01 DFHCOMMAREA.
05 CA-ACCOUNT-ID PIC X(12).
05 CA-BALANCE PIC S9(13)V99 COMP-3.
05 CA-STATUS PIC X(2).
PROCEDURE DIVISION.
MOVE CA-ACCOUNT-ID TO WS-ACCOUNT-ID
EXEC SQL
SELECT BALANCE
INTO :WS-BALANCE
FROM ACCOUNTS
WHERE ACCOUNT_ID = :WS-ACCOUNT-ID
END-EXEC
IF SQLCODE = 0
MOVE WS-BALANCE TO CA-BALANCE
MOVE 'OK' TO CA-STATUS
ELSE
MOVE 'ER' TO CA-STATUS
END-IF
EXEC CICS RETURN END-EXEC.Die Umsetzung in Java sieht wie folgt aus:
@RestController
@RequestMapping("/accounts")
public class AccountController {
private final AccountService accountService;
public AccountController(AccountService accountService) {
this.accountService = accountService;
}
@GetMapping("/{id}/balance")
public ResponseEntity<AccountBalanceResponse> getBalance(@PathVariable String id) {
BigDecimal balance = accountService.getBalance(id);
if (balance != null) {
return ResponseEntity.ok(new AccountBalanceResponse(id, balance, "OK"));
} else {
return ResponseEntity.status(HttpStatus.NOT_FOUND)
.body(new AccountBalanceResponse(id, null, "ER"));
}
}
}Fehlerquellen und Gegenmaßnahmen
Wie bei jeder Softwareentwicklung treten auch bei der Legacy-Migration von COBOL nach Kubernetes verschiedene Herausforderungen auf, die rechtzeitig beachtet werden sollten:
Unterschiedliche Transaktionsgrenzen
CICS verwaltet seine eigene Unit of Work. Wird ein Service nach Kubernetes ausgelagert, entfällt diese implizite Transaktionsgrenze. Werden in einem COBOL-Programm mehrere DB2-Schreibvorgänge innerhalb einer einzigen CICS-Transaktion ausgeführt, braucht die containerisierte Version eine klar definierte Transaktionslogik. Wird das übersehen, können unter Last unvollständige Schreibvorgänge auftreten.
Ein populärer Ansatz zur Lösung ist das Saga-Pattern für verteilte Transaktionen. Jeder Schritt wird durch eine entsprechende Ausgleichsaktion ergänzt. Das erhöht die Komplexität, bildet jedoch die Realität verteilter Systeme korrekt ab.
Batch- vs. Echtzeitverarbeitung
JES2-Batch-Jobs besitzen Planungslogiken, die keine direkte Entsprechung in Kubernetes CronJobs haben. Ein JES2-Job hat Prioritäten, Jobklassen und Initiator-Zuordnungen. Ein Kubernetes CronJob dagegen basiert auf einem Zeitplan und einer Pod-Definition. Bei komplexeren Abhängigkeiten, etwa wenn Job A vor Job B abgeschlossen sein muss, wird häufig eine zusätzliche Orchestrierungsschicht benötigt. Typische Lösungen sind Apache Airflow oder Argo Workflows.
DB2-Cursor-Scope
Einige COBOL-Programme öffnen DB2-Cursor und halten diese über mehrere CICS-Aufrufe aktiv. Container hingegen sind zustandslos. Sobald eine Anfrage abgeschlossen ist, geht auch der Cursor-Zustand verloren. In solchen Fällen ist vor der Extraktion eine strukturelle Anpassung notwendig.
Zeichenkodierung
z/OS verwendet EBCDIC, während moderne Systeme auf ASCII oder UTF-8 basieren. Daten aus DB2 auf z/OS, VSAM-Dateien oder MQ-Queues müssen daher korrekt konvertiert werden. Wird dies unterschätzt, führt es häufig zu Problemen im Produktivbetrieb, z.B. durch fehlerhafte Stringvergleiche oder falsche Dezimalverarbeitung in numerischen Feldern.
Fazit
Die Migration von COBOL nach Kubernetes ist kein einzelnes Projekt, sondern eine schrittweise architektonische Transformation. Sie erfolgt Service für Service und kann sich über Monate oder sogar Jahre erstrecken.
Teams, die diese Rahmenbedingungen ignorieren, verlassen sich letztlich auf Zufall. Manchmal funktioniert das, häufig aber nicht. Die Folge sind hektische Hotfixes und Rollbacks unter Zeitdruck, was unnötige Kosten verursacht.
Entscheidend für den Erfolg ist die Klärung einiger zentraler Fragen: Welche Komponenten werden zuerst extrahiert, wie wird die DB2-Migration umgesetzt und wie wird mit Abhängigkeiten in Batch-Prozessen umgegangen. Weitere Aspekte ergeben sich je nach Geschäftslogik des jeweiligen Unternehmens.
Diese Entscheidungen sollten von Experten getroffen werden, die das bestehende System im Detail verstehen. Eine universelle Lösung gibt es nicht.
Das Strangler-Pattern bietet hierfür einen strukturierten Ansatz. Es ermöglicht eine schrittweise Migration mit Rückfalloptionen, anstatt alles auf einmal umzustellen. COBOL selbst ist nicht das eigentliche Problem. Entscheidend ist das zugrunde liegende Betriebs- und Bereitstellungsmodell.