Unternehmens-Altsysteme ohne radikalen System-Neubau modernisieren: Ein praxisnahes Architektur-Playbook
In jedem Enterprise-Entwicklungsteam entsteht irgendwann das Thema der Modernisierung von Altsystemen. Es geht um die Systeme, die seit vielen Jahren existieren und die Abrechnung, Auftragsmanagement oder andere geschäftskritische Prozesse steuern. In den meisten Fällen sind die Architekten, die diese Systeme entwickelt haben, nicht mehr ein Teil des Teams, Tests sind nur teilweise vorhanden und die Dokumentation ist lückenhaft. Ein großer Teil des Wissens über die Funktionsweise der Anwendung beruht auf informellem Wissen, das innerhalb des Teams weitergegeben wird.
Die entscheidende Frage ist nicht, ob das System verändert werden muss, sondern ob eine vollständige Neuschreibung tatsächlich die richtige Lösung ist.
In den meisten Fällen ist sie es nicht.
Dieser Artikel beschreibt einen schrittweisen Ansatz zur Modernisierung von Legacy-Anwendungen: wie sich Funktionen schrittweise aus dem Altsystem auslagern lassen, wie veraltete Schnittstellen hinter klaren Verträgen gekapselt werden können, wie eine Migration in Cloud-Infrastruktur gelingt, ohne den laufenden Betrieb zu gefährden, und wie sich der Codebestand nach und nach refaktorieren lässt, während das System weiterhin stabil läuft. Diese Vorgehensweisen wurden in Umgebungen eingesetzt, in denen Ausfallzeiten keine Option waren und Fehlentscheidungen nicht nur technische Probleme, sondern finanzielle Verluste oder Compliance-Risiken bedeutet hätten.
Warum vollständige Neuschreibungen immer wieder scheitern
Legacy-Systeme verbinden häufig architektonische und technische Probleme. Ein unübersichtliches Datenmodell, unklare Prozesse und eine Codebasis ohne transparente Struktur, die nur schwer zu warten ist. Vor diesem Hintergrund wirkt eine vollständige Neuschreibung oft wie eine Chance, ein schwer zu wartendes System endlich zu ersetzen
Das Problem ist jedoch, dass solche Systeme meist über die Jahre entstandene implizite Systemlogik enthalten. Sonderfälle. Workarounds für Fehler in vorgelagerten Systemen. Sonderregelungen für bestimmte Kunden. Kaum etwas davon ist dokumentiert, und vieles wird erst sichtbar, wenn eine Neuschreibung diese Logik falsch abbildet.
Angenommen, man entscheidet sich trotzdem für diesen Weg. Sobald ein neues System entwickelt wird, zeigt sie sofort Fehlermeldungen, die im alten System unbemerkt abgefangen wurden. Diese Situation ist für das Unternehmen inakzeptabel, daher bleibt das alte System als Fallback bestehen. Nun müssen zwei Systeme parallel gepflegt werden. Joel Spolsky hat diese Dynamik bereits in den 2000er-Jahren in seinem Beitrag „Things You Should Never Do“ beschrieben. Das Problem von Neuschreibungen ist also nicht neu, tritt aber immer wieder auf, weil die Probleme des bestehenden Systems offensichtlich sind, während seine Komplexität oft unterschätzt wird.
Das Strangler-Fig-Pattern als Ausgangspunkt
Eine der besten Strategien für die schrittweise Modernisierung von Legacy-Systemen ist das Strangler-Fig-Pattern, geprägt von Martin Fowler. Die Idee basiert auf Baumarten, die um einen Wirtsbaum wachsen und diesen nach und nach ersetzen. Übertragen auf die Softwareentwicklung bedeutet das, ein neues System schrittweise um das bestehende Legacy-System herum aufzubauen. Nach jeder implementierten Komponente wird der Datenverkehr vom alten Teil auf den neuen umgeleitet, getestet und validiert. Nach mehreren Iterationen wird das alte System vollständig ersetzt.
Für die Systemarchitektur bedeutet das:
- Einen klar abgegrenzten Funktionsbereich bestimmen
- Den Ersatz parallel zum Legacy-System (oder davor) entwickeln
- Neuen Datenverkehr gezielt über den neuen Pfad führen
- Bestehenden Datenverkehr schrittweise umstellen
- Alte Komponente abschalten, sobald der gesamte Verkehr erfolgreich umgeleitet ist
Der größte Vorteil dieses Ansatzes liegt darin, dass sich Änderungen einfach zurückrollen lassen. Wenn nach der Einführung einer neuen Komponente Probleme auftreten, wird der Datenverkehr einfach wieder auf das alte System geleitet. Im Vergleich zu einer vollständigen Neuschreibung reduziert das das Risiko erheblich.
Die Verkehrssteuerung in den Schritten 3 und 4 erfolgt häufig über Feature-Flags oder einfache Proxy-Regeln. Im Folgenden wird ein kleines Beispiel für einen flagbasierten Router gezeigt, der zwei Implementierungen ansteuert:
# nginx routing rule -- shift traffic gradually to new service
# Start at 5%, increase as confidence grows
upstream legacy_service {
server legacy-app:8080;
}
upstream new_service {
server new-app:8080;
}
split_clients '${remote_addr}AAA' $backend {
5% new_service; # 5% to new implementation
* legacy_service; # remainder to legacy
}
location /orders/ {
proxy_pass http://$backend;
}Sollte im neuen System etwas fehlschlagen, wird mit minimalem Aufwand wieder das alte System aktiviert und übernimmt 100 % des Datenverkehrs. Monitoring und Instrumentierung auf beiden Upstream-Systemen ermöglichen es, Fehlerraten und Latenzen zu vergleichen, bevor eine vollständige Umstellung erfolgt.
Modulare Extraktionsstrategie
Unter modularer Extraktion versteht man die Identifikation von Legacy-Komponenten, die sich vom Systemkern entkoppeln lassen, ohne das Gesamtsystem zu destabilisieren. Dabei orientiert man sich in der Regel an einer Microservices-Strategie. Dies ist der erste konkrete Schritt in jedem Modernisierungsplan für Enterprise-Altsysteme.
Wichtig ist an dieser Stelle zu verstehen, dass sich nicht alle Komponenten sauber extrahieren lassen. Um passende Kandidaten zu finden, sollten insbesondere die Teile berücksichtigt werden, die folgende Eigenschaften aufweisen:
- klare Ein- und Ausgabeschnittstellen, sodass eindeutig definiert ist, welche Daten eingehen und welche Ergebnisse zurückgegeben werden
- kleine Abhängigkeiten zum restlichen System
- weitgehend nachvollziehbares Verhalten, auch ohne umfassende Testabdeckung
- ein klarer Modernisierungsgrund, etwa Leistung, Wartbarkeit oder Integration in eine Unternehmensarchitektur
Um Legacy-Teile zu identifizieren, sollte man das Deployment-Modell analysieren. Welche Komponenten müssen unabhängig voneinander geändert werden? Welche Teile lösen bei Deployments regelmäßig Fehler aus? Genau dort lassen sich in der Regel die natürlichen Systemgrenzen erkennen.
Sobald ein Modul identifiziert wurde, erfolgt die Extraktion typischerweise so:
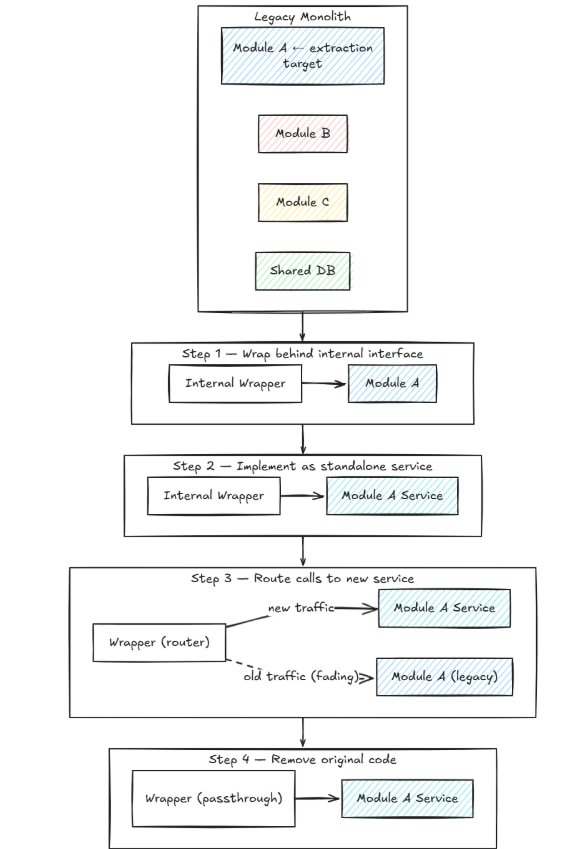
Diesen Ansatz findet man in der serviceorientierten Architektur-Migration häufig unter der Bezeichnung Module-to-Service-Pfad. Entscheidend ist dabei die klare Abgrenzung zu Microservices-from-scratch: Hier wird die bestehende Systemstruktur schrittweise weiterentwickelt, statt eine vollständig neue Systemarchitektur zu entwerfen.
Nicht zuletzt spielen gemeinsam genutzte Datenbanken eine Rolle. Sowohl der Monolith als auch der extrahierte Service basieren in der Regel auf derselben Datenbank, da gleichzeitige Änderungen an beiden Seiten ein zu hohes Risiko darstellen würden. Das ist akzeptabel, denn die Entkopplung der Datenbank erfolgt in einem späteren Schritt, sobald die Servicegrenzen stabil definiert sind.
API-Wrapping für Legacy-Anwendungen
Eine API als Wrapper für Legacy-Anwendungen einzusetzen, ist eine weitere sinnvolle Strategie im Rahmen eines Modernisierungsplans. Die Grundidee ist einfach: Vor das bestehende System wird eine API-Schicht gesetzt, die klar definierte Schnittstellen für alle Consumer bereitstellt und gleichzeitig die internen Implementierungsdetails des Legacy-Systems kapselt.
In der Praxis wird dieser Ansatz häufig unterschätzt, obwohl er oft den geringsten Eingriff trotz hoher Wirkung ermöglicht. Der größte Vorteil besteht darin, die externe Systemoberfläche zu kontrollieren. Änderungen innerhalb der Legacy-Anwendung können von der API-Schicht abgefangen werden, ohne dass Consumer direkt betroffen sind. Zusätzlich entsteht ein zentraler Instrumentierungspunkt, an dem sich Logging, Rate Limiting, Authentifizierung und Monitoring integrieren lassen, ohne den Systemkern zu verändern.
Ein typisches Setup folgt dabei einer klaren Struktur:
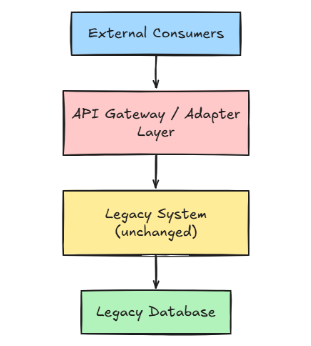
Beispielsweise gibt es beim Legacy-System einen SOAP-Endpunkt:
<GetCustomerRequest>
<CustomerID>12345</CustomerID>
<IncludeHistory>true</IncludeHistory>
</GetCustomerRequest>Der Wrapper stellt alternativ einen REST-Endpunkt bereit:
GET /customers/12345?includeHistory=trueEine genauere Analyse der Implementierung zeigt, dass der Wrapper als eine Art Übersetzer betrachtet werden kann. Er nimmt die Anfragen entgegen, übersetzt sie in den SOAP-Aufruf, wertet die Antwort aus und liefert den Verbrauchern ein JSON zurück. Die SOAP-Schicht bleibt für sie unsichtbar. Wenn das Legacy-System später ersetzt wird, bleiben die Schnittstellen unverändert, sodass für die Verbraucher keine Anpassungen erforderlich sind.
Der größte Nachteil liegt hier in der Latenz. Es wird ein zusätzlicher Verarbeitungsschritt eingefügt. Bei hochvolumigen, latenzsensitiven Pfaden ist dies relevant und sollte gemessen werden. Bei den meisten internen Enterprise-APIs lohnt sich der Aufwand, da die betrieblichen Vorteile größer sind als die Kosten.
Hybrid-Cloud-Migration für Enterprise-Altsysteme
Eine weitere Strategie besteht darin, ein Legacy-System in die Cloud zu migrieren. In diesem Fall ist ein hybrider Ansatz üblich, bei dem Teile des Systems auf der bestehenden Infrastruktur betrieben werden, während andere Komponenten auf Cloud-Services verlagert werden. Dies ist in der Regel die sinnvollste Vorgehensweise, um eine cloud-native Transformation von Systemen durchzuführen, die nicht offline genommen werden können.
Eine typische Vorgehensweise bei der Hybrid-Cloud-Migration von Legacy-Systemen sieht folgend aus:

Hier ist die Wahrheit: Viele Unternehmen erreichen Phase 2 oder 3 und verbleiben dort — die Legacy-Datenbank bleibt dauerhaft On-Prem, da das Migrationsrisiko zu hoch ist. Das ist ein legitimes Ergebnis und kein Fehler.
Die größte Herausforderung bei hybriden Setups liegt in Netzwerk und Datensynchronisation. Ein Cloud-Service, der auf eine On-Prem-Datenbank zugreift, muss Latenzzeiten in Kauf nehmen und erzeugt einen einzelnen Fehlerpunkt. Um diese Risiken zu reduzieren, ist eine Change-Data-Capture-Schicht eine der zuverlässigsten Lösungen. Jede Änderung in der Datenbank, wie Einfügen, Aktualisieren, Löschen, wird auf Kafka-Topic veröffentlicht.
Eine Debezium-Connector-Konfiguration für eine PostgreSQL-Quelle sieht folgendermaßen aus:
{
"name": "legacy-products_cart-cdc",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "legacy-db.internal",
"database.port": "5432",
"database.user": "replication_user",
"database.dbname": "products_cart",
"table.include.list": "public.products_cart,public.products_cart_items",
"topic.prefix": "legacy",
"slot.name": "debezium_slot",
"plugin.name": "pgoutput"
}
}Cloud-Consumer abonnieren diese Topics in einer Cloud-Datenbank oder in einem Data Warehouse. Das Legacy-System schreibt wie bisher in seine Datenbank, während die CDC-Schicht die Änderungen im Hintergrund erfasst.
Der gleichzeitige Betrieb von zwei Umgebungen führt zu höherer operativer Komplexität, da beide regelmäßig überwacht und abgesichert werden müssen. Dieser Aspekt wird häufig unterschätzt, daher ist eine sorgfältige Planung der Implementierung unerlässlich.
Inkrementelles Refactoring
Modulare Extraktion und API-Wrapping betreffen vor allem die Systemarchitektur. Bei der inkrementellen Modernisierung von Legacy-Anwendungen geht es hauptsächlich darum, kleine Verbesserungen im bestehenden Code vorzunehmen, ohne das Verhalten des Systems stark zu verändern. Jedes Mal, wenn ein Modul für ein neues Feature oder ein Bugfix angepasst wird, erfolgt eine kleine Verbesserung: eine unklare Variable wird umbenannt, eine lange Methode wird aufgeteilt oder ein bisher fehlender Test wird ergänzt.
Der Fortschritt ist langsam und liefert keine spektakulären Vorher-Nachher-Kennzahlen, doch genau hier wird der größte Teil der technischen Schulden reduziert. Durch konsequente Anwendung des Boy-Scout-Prinzips, also den Code in einem besseren Zustand zu hinterlassen als vorgefunden, werden die Verbesserungen über 12 bis 18 Monate in einer aktiven Codebasis deutlich sichtbar
Dieser Ansatz erleichtert auch eine spätere Modul-Extraktion. Sobald ein Modul über klar definierte Schnittstellen, eine sinnvolle Testabdeckung und nur geringe versteckte Abhängigkeiten über Systemgrenzen hinweg verfügt, sinkt das Risiko einer Extraktion erheblich.
Für diesen Zweck stehen verschiedene Muster und Techniken zur Verfügung. Häufig kommt dabei eine Übersetzungsschicht zum Einsatz, wenn das Legacy-System ein Domänenmodell verwendet, das nicht zur angestrebten Zielarchitektur passt, etwa durch unterschiedliche Begriffe oder Datenstrukturen oder implizite Annahmen im Datenmodell. Dieser Ansatz ist in Domain-Driven Design als Anti-Corruption-Layer bekannt. Nach der Einführung dieser Schicht wird sichergestellt, dass neuer Code auf den richtigen Konzepten basiert, ohne vom Legacy-Modell beeinflusst zu werden.
Für Projekte mit stark gekoppeltem Code und schwacher Testabdeckung, was auf viele Legacy-Codebasen zutrifft, ist die Mikado-Methode besonders hilfreich. Das Prinzip ist einfach: Sobald ein Refactoring erforderlich ist, wird zunächst der erste Versuch durchgeführt. Wenn der Code kompiliert, alle Tests bestehen und das System korrekt funktioniert, ist der Schritt abgeschlossen. Treten Fehler auf, werden alle Kompilierungsfehler und fehlgeschlagenen Tests dokumentiert, die Änderung wird zurückgesetzt, und die notwendigen Voraussetzungen werden zuerst umgesetzt, indem der gleiche Ablauf wiederholt wird. Dabei können weitere Abhängigkeiten sichtbar werden, wodurch nach und nach eine Art Abhängigkeitsgraph entsteht. Am Ende liegt eine klare Übersicht darüber vor, welche Änderungen notwendig sind, bevor die ursprüngliche Anpassung sicher umgesetzt werden kann. Problematische Änderungen werden rechtzeitig zurückgerollt, sodass der Main-Branch stabil bleibt. Dieser Prozess ist langsamer als ein direkter Eingriff in den Code, liefert bei komplexen Legacy-Systemen jedoch oft das realistischste Bild der internen Abhängigkeiten.
Praktische Roadmap zur Legacy-Modernisierung
Im Projektalltag setzt man diese Strategien meist parallel und nicht in einer strikten Reihenfolge ein. In einem Modul wird inkrementelles Refactoring durchgeführt, in einem anderen API-Wrapping umgesetzt, während für ein drittes bereits eine Cloud-Migration geplant wird. Als Orientierungshilfe zeigt die folgende Grafik eine typische Modernisierungs-Roadmap:
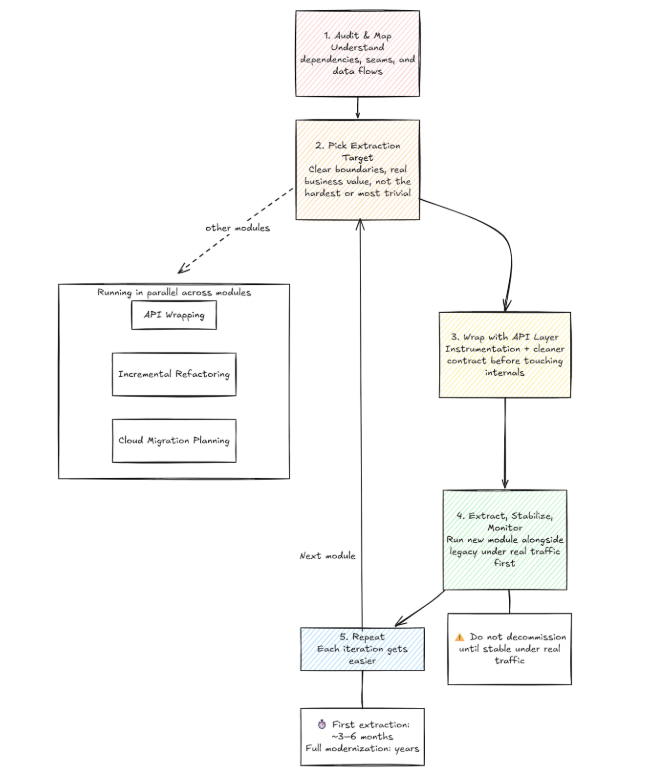
Fazit
Die Modernisierung von Enterprise-Altsystemen ist vor allem eine Frage der richtigen Reihenfolge. Anstatt alles neu zu entwickeln und darauf zu hoffen, dass es sofort funktioniert, geht es um einen strukturierten Ansatz: die passende Trennstelle identifizieren, kapseln, extrahieren und den Prozess wiederholen, während das System kontinuierlich weiterläuft.
Die in den vorherigen Abschnitten beschriebenen Techniken wie Strangler-Fig-Pattern, modulare Extraktion, API-Wrapping, CDC-basierte Synchronisation, inkrementelles Refactoring und die Mikado-Methode sind hilfreiche Werkzeuge, um dieses Ziel zu erreichen. Keine dieser Methoden ist jedoch eine Universallösung.
Der Erfolg hängt vor allem davon ab, die passenden Werkzeuge zum richtigen Zeitpunkt einzusetzen und sie auf System und Team abzustimmen. Organisationen, die diesen Ansatz richtig anwenden, haben oft eine gemeinsame Denkweise: Sie betrachten Modernisierung als kontinuierlichen Entwicklungsprozess und nicht als festes Projekt. Ziel ist ein System, das in sechs Monaten spürbar einfacher zu betreiben ist und sich danach Schritt für Schritt weiter verbessert.