KI-gestützte Softwareentwicklung: Best Practices für moderne Entwicklerteams
GitHub Copilot, Cursor und Claude sind nur einige Beispiele für Tools, die von Entwicklerteams als fester Bestandteil ihrer Arbeitsabläufe eingesetzt werden. Ob in Kommandozeilen-Tools, Editoren oder CI-Pipelines – in Unternehmen jeder Größe gehören sie zum Arbeitsalltag jedes Entwicklers.
Die Auswirkungen sind leicht messbar: schnellere Codevervollständigung, weniger Zeitaufwand für Boilerplate-Code, schnellere Testabdeckung. Das ist unbestritten.
Es gibt jedoch eine andere Seite, die weniger Beachtung findet. KI-generierter Code birgt Sicherheitslücken, Lizenzfragen und einen erhöhten Wartungsaufwand. Fehler sind subtil und manchmal schwer zu erkennen. Sie entgehen der Code-Review. Teams, die diese Tools einführen, ohne ihre Prozesse anzupassen, bemerken die Probleme oft erst spät.
In den folgenden Abschnitten betrachten wir die Disziplin bei der KI-gestützten Softwareentwicklung und die erforderlichen Entwicklungspraktiken für den sicheren Einsatz dieser Tools in Produktionsumgebungen. Wir zeigen Ihnen die Erfahrungen von Chudovo zu diesem Thema: Was funktioniert, was nicht und welche Maßnahmen sollten getroffen werden, bevor KI-generierter Code in der Produktion eingesetzt wird?
Was ist KI-gestützte Softwareentwicklung?
Kurz gesagt, bezeichnet sie den Einsatz KI-gestützter Tools, die Entwickler beim Schreiben, Überprüfen, Testen und Dokumentieren von Code unterstützen.
Typische Anwendungsfälle sind:
- Automatische Codevervollständigung während der Eingabe
- Generierung von Boilerplate-Code oder wiederkehrenden Strukturen
- Vorschläge zur Behebung von Testfehlern
- Erstellung von Dokumentation aus dem Code
- Erläuterung unbekannter Codebasen
- Brainstorming von Architekturoptionen
KI-gestützte Entwicklung ist nicht dasselbe wie vollständige Automatisierung. Letztere impliziert, dass ein KI-System Infrastruktur bereitstellt oder Pull Requests ohne Überprüfung zusammenführt. Dies fällt in eine andere Kategorie und birgt ein höheres Risiko. Bei der KI-gestützten Entwicklung trifft der Entwickler die Entscheidungen, und die KI liefert Optionen und Details.
So arbeiten die meisten Teams üblicherweise: KI als schneller Kollaborateur, der jedoch vor der Auslieferung noch eine Freigabe benötigt.
Welche KI-Programmierassistenten nutzen Ingenieure tatsächlich?
KI-Assistenten lassen sich leicht in drei Hauptkategorien einteilen:
IDE-integrierte Assistenten. Diese Assistenten sind direkt im Editor integriert. GitHub Copilot ist der am weitesten verbreitete. Cursor ist ein VS Code-Fork, der vollständig auf KI-Workflows basiert und Kontext für mehrere Dateien sowie Bearbeitungen im Agentenmodus bietet. JetBrains AI Assistant deckt ähnliche Bereiche für Teams ab, die bereits mit IntelliJ arbeiten.
Konversationelle Assistenten wie Claude, ChatGPT und Gemini eignen sich gut für Aufgaben, die nicht direkt in einen Textcursor passen. Architekturdiskussionen, Debugging-Sitzungen, Überarbeitung von Dokumentationen und die Analyse komplexer regulärer Ausdrücke sind Beispiele dafür. Man fügt den Kontext ein, bespricht das Problem und arbeitet iterativ.
Spezialisierte Tools decken spezifischere Anwendungsfälle ab. Tabnine konzentriert sich auf Codevervollständigung mit einer Option für lokale Modelle (dies ist besonders nützlich für Unternehmen mit Anforderungen an den Datenstandort). Codeium bietet eine kostenlose Version, die von vielen einzelnen Entwicklern genutzt wird. Open-Source-Modelle wie DeepSeek werden zunehmend in selbstgehosteten Umgebungen für Teams mit strengeren Datenschutzrichtlinien eingesetzt.
Während lokale Tools vollständig auf dem Rechner des Entwicklers mit clientseitiger Hardware laufen, nutzen selbstgehostete Bereitstellungen eine private Cloud-Infrastruktur (wie einen AWS- oder GCP-Cluster für Unternehmen), um Open-Wave-Modelle sicher für das gesamte Entwicklerteam bereitzustellen, ohne dass Daten nach außen gelangen.
Die folgende Tabelle bietet einen schnellen Vergleich der aktuell beliebtesten Tools:
| Tool | Am besten geeignet für | Preismodell |
| GitHub Copilot | Code-Vervollständigung im Editor, PR-Zusammenfassungen | Benutzerbasierte Lizenz (Per-Seat-Abonnement) |
| Cursor | Dateiübergreifende Bearbeitungen, Agenten-Workflows | Benutzerbasierte Lizenz (Per-Seat-Abonnement) |
| Claude | Komplexe Codegenerierung, Verarbeitung langer Kontexte und Softwarearchitektur | API / per-seat |
| ChatGPT / GPT-4o | Allgemeine Programmierfragen, Debugging | API / per-seat |
| Tabnine | Code-Vervollständigung mit Datenschutz- und Privatsphäre-Funktionen | Per-Seat, auch als Self-Hosted-Lösung verfügbar |
Moderne IDEs beginnen auch damit, native KI-gestützte Funktionen wie die Generierung von Commit-Nachrichten, Inline-Code-Erklärungen und KI-gestützte Refactoring-Tools anzubieten.
Wie Entwickler KI in ihren täglichen Programmier-Workflow integrieren
Entwicklerteams nutzen KI-Tools in verschiedenen Phasen ihres Workflows und für unterschiedliche Zwecke. Die wohl direkteste Anwendung ist die Codegenerierung. Man gibt dem Modell eine Funktionssignatur, einen Docstring oder eine Beschreibung in einfacher Sprache, und es generiert eine Implementierung. Für die Implementierung von Standardmustern wie CRUD-Operationen, Datentransformationen und API-Clients ist dieser Ansatz hervorragend geeignet. Weniger gut funktioniert er für domänenspezifische Geschäftslogik oder solche, die von undokumentiertem internem Verhalten abhängt.
Ein weiterer wichtiger Anwendungsbereich ist das Refactoring. Man fügt eine Funktion ein und bittet die KI, sie zu vereinfachen, wiederholte Logik zu extrahieren oder Elemente konsistent umzubenennen. Das ist oft schneller als die manuelle Vorgehensweise und erzeugt einen Diff, den man überprüfen kann. Aber Vorsicht: Modelle vereinfachen manchmal so, dass unbemerkt Grenzfälle nicht mehr funktionieren. Daher muss man das Endergebnis im Auge behalten.
Debugging mithilfe von KI ist überraschend effektiv. Durch das Teilen eines einfachen Stack-Traces oder die Beschreibung einer unerwarteten Ausgabe kann das Modell die wahrscheinlichen Ursachen schnell eingrenzen. Natürlich ersetzt es nicht das Verständnis Ihres Systems (hierfür müssen Sie es unterstützen), aber es überspringt die ersten zwanzig Minuten der allgemeinen Suche.
KI-Tools für Softwaretests eignen sich besonders gut für einfache Funktionen und vorhersehbare Validierungsszenarien. Ausgehend von einer Funktion und ihrem erwarteten Verhalten erzeugt das Modell schnell eine angemessene Unit-Test-Abdeckung. Für Integrationstests oder Tests, die von externen Zuständen abhängen, ist jedoch weiterhin menschliches Design erforderlich.
Dokumentation ist einer der größten Vorteile. Modelle wandeln Code zuverlässig in lesbaren Text um: Docstrings, READMEs, API-Beschreibungen. Manchmal muss die Ausgabe noch bearbeitet werden, aber sie ist ein guter Ausgangspunkt.
Eine oft unterschätzte Anwendung ist das Brainstorming zur Architektur. Angenommen, Sie müssen sich zwischen zwei (oder mehr) Entwurfsmustern entscheiden. Sie können nach den Vor- und Nachteilen fragen und erhalten einen strukturierten Vergleich, auf den Sie reagieren können. Beachten Sie jedoch: Das Modell kennt Ihre Einschränkungen nur, wenn Sie sie ihm mitteilen. Formulieren Sie Ihre Anfrage daher explizit.
Schnelle Unterstützung für Entwickler ist wichtig. Kleine Änderungen im Kontext und in der Spezifität führen zu sehr unterschiedlichen Ergebnissen. Daher müssen Sie experimentieren, verfeinern und iterativ vorgehen, um die Ergebnisse des Modells zu verbessern.
Hier ist eine Eingabeaufforderung, die das Team von Chudovo für die strukturierte Codegenerierung als effektiv empfunden hat:
You are a senior Python engineer.
Context: FastAPI service, PostgreSQL backend, SQLAlchemy ORM.
Task: Write a repository class for the Order model with methods:
- get_by_id(order_id: int) -> Order | None
- list_by_user(user_id: int, limit: int = 50) -> list[Order]
- create(data: OrderCreate) -> Order
- update_status(order_id: int, status: OrderStatus) -> Order | None
Requirements:
- Use async SQLAlchemy sessions (SQLAlchemy 2.0+ style select statements).
- Include proper type hints.
- Raise ValueError in update_status if order not found.
Return only the class, no explanation.Der Hauptgrund hierfür ist die Spezifität. Methodensignaturen mit expliziten Typangaben, die Anforderung der Asynchronität und die `raiseValueError`-Anweisung schließen die Lücke zwischen einem generischen Code-Snippet und einem Code, der sich direkt in eine reale Codebasis einfügen lässt.
Unpräzise Vorgaben führen zu unpräzisem Code. Durch die Angabe des Technologie-Stacks, der Einschränkungen und des exakten Ausgabeformats erhält man ein Ergebnis, das deutlich besser in die Praxis passt.
Wo KI die Entwicklerproduktivität am meisten steigert
Der Hauptgrund für den Einsatz KI-gestützter Tools ist die Steigerung der Produktivität. Dies lässt sich auf verschiedene Weise erreichen:
- Reduzierung von Routinearbeiten: Das Modell übernimmt Boilerplate-Code, Scaffolding, Konfigurationsdateien, Serialisierung und Migrationen. Kurz gesagt: all die notwendigen, aber selten interessanten Aufgaben. KI erledigt diese Aufgaben schneller als Entwickler, und die Einsparungen summieren sich bei großen Codebasen.
- Onboarding: Neue Teammitglieder können KI bitten, unbekannten Code zu erklären, die Funktion eines Dienstes zusammenzufassen oder ein unbekanntes Modul zu erläutern. Erfahrene Entwickler verbringen weniger Zeit mit Einarbeitungsfragen. KI ersetzt zwar nicht die Mentorschaft, verändert aber das Verhältnis.
- Prototyping: Mit KI erhalten Sie innerhalb von Stunden statt Tagen einen funktionsfähigen Proof of Concept. Dies schafft echten Mehrwert, da Teams Ideen kostengünstiger und früher validieren können. Die Qualität ist oft ausreichend für eine interne Demo oder die Prüfung durch Stakeholder.
- Kontextwechsel: Entwickler wechseln ständig zwischen verschiedenen Aufgaben. Wenn Sie zu Code zurückkehren, den Sie drei Wochen lang nicht bearbeitet haben, hilft KI Ihnen, Ihr mentales Modell schneller wiederherzustellen, als wenn Sie nur die Git-Historie durchlesen.
Risiken, die Sie einplanen sollten
KI-Tools können Entwicklungsteams zwar unterstützen, doch hat die KI-gestützte Softwareentwicklung bereits zu dokumentierten Produktionsausfällen geführt, wenn sich die Teams zu stark auf generierte Ergebnisse ohne ausreichende Validierung verlassen. Im Folgenden sind einige dokumentierte Fehlermodi aufgeführt.
Halluzinationen
In einigen Fällen erzeugen Modelle Code, der plausibel aussieht, aber nicht funktioniert. Dies geschieht meist bei weniger verbreiteten Bibliotheken, Sonderfällen oder bei Aufgaben, die echtes Wissen über Ihr internes System erfordern. Eine Funktion, die korrekt aussieht, aber stillschweigend Datensätze verwirft, kann die Code-Review passieren und erst in der Produktionsumgebung fehlschlagen.
Sicherheitslücken
Untersuchungen haben gezeigt, dass Modelle unsichere Muster reproduzieren können, die in den Trainingsdaten enthalten sind. Dazu gehören beispielsweise fest codierte Zugangsdaten, SQL-Injections durch Zeichenkettenverkettung oder eine fehlende Eingabevalidierung. Wenn Sie für KI-generierten Code keine Sicherheitsscans durchführen, gehen Sie ein unbekanntes Risiko ein.
Betrachten wir das folgende Beispiel:
# Insecure AI-generated example
query = f"SELECT * FROM users WHERE email = '{email}'"
cursor.execute(query)Durch Zeichenkettenverkettung erstellte SQL-Abfragen kommen in KI-generiertem Code noch immer häufig vor, insbesondere wenn Prompts zu vage formuliert sind oder keine Sicherheitsanforderungen enthalten.
Halluzinierte Pakete
Modelle erfinden häufig Abhängigkeiten oder Bibliotheken, die gar nicht existieren. Wenn Entwickler solche Pakete ungeprüft installieren, besteht das Risiko, dass sie bösartige Typosquatting-Bibliotheken herunterladen, die von Angreifern in Registries wie PyPI oder npm registriert wurden.
Unsicherheit bei Lizenzrechten
Von KI-Modellen erzeugter Code kann urheberrechtlich geschützte Inhalte aus den Trainingsdaten widerspiegeln. Die rechtliche Situation ist nach wie vor nicht eindeutig. Unternehmen, deren Produkte besonders sensibel in Bezug auf geistiges Eigentum sind, sollten daher vor dem großflächigen Einsatz von KI-Programmierwerkzeugen klare Richtlinien festlegen.
Schlechte Wartbarkeit
KI-generierter Code priorisiert häufig Geschwindigkeit gegenüber dem Kontext, den zukünftige Entwickler benötigen. Kommentare sind oft knapp, und Abstraktionen werden eher für eine schnelle Vervollständigung als für Klarheit gewählt. Auch die Benennung von Variablen, Funktionen oder Klassen kann sehr generisch ausfallen. Diese Aspekte sollten bei Code-Reviews berücksichtigt werden.
Übermäßige Abhängigkeit
Entwickler, die sich bei jeder Aufgabe auf KI verlassen, können mit der Zeit die Fähigkeit verlieren, KI-generierte Ergebnisse kritisch zu bewerten. Modelle liegen keineswegs selten falsch. Solche Fehler zu erkennen, erfordert Urteilsvermögen – und dieses kann ohne regelmäßige Praxis nachlassen.
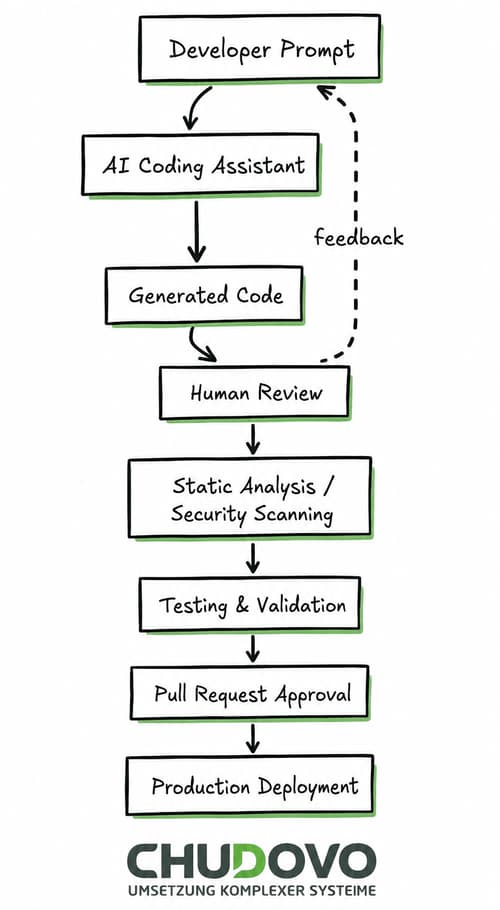
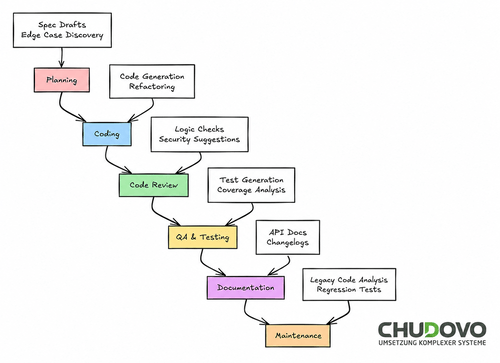
Typischer KI-gestützter Entwicklungsablauf mit manueller Validierung
Das folgende Schema veranschaulicht, wie das Team von Chudovo mithilfe von KI-Tools iterativ sichere und validierte Ergebnisse liefert.
Best Practices für Teams
Eine der wichtigsten Sicherheitsvorkehrungen für jedes Entwicklungsteam ist ein KI-gestützter Code-Review-Prozess. Die KI-generierte Ausgabe ist lediglich ein erster Entwurf und darf erst nach der Prüfung durch einen Reviewer veröffentlicht werden.
Ergänzt wird dies durch statische Codeanalyse und Sicherheits-Scans im Rahmen der CI-Pipeline. SAST-Tools wie Semgrep, Bandit und Snyk sind hierbei hilfreich. In der Praxis werden diese Prüfungen direkt in die Validierungspipelines für Pull Requests integriert, um zu verhindern, dass unsicherer generierter Code in die Produktionsumgebung gelangt.
# Example CI validation step
- name: Run security scan
run: semgrep --config=autoEine weitere bewährte Methode ist die Festlegung gemeinsamer Muster für die Codeerstellung im Team. Mindestens sollten Sie Folgendes festlegen:
Ihren Technologie-Stack und die gemeinsam genutzte Codebasis, die wiederverwendet werden soll (globale Variablen, Stile, Hilfsfunktionen usw.).
Einschränkungen, die während der Entwicklung berücksichtigt werden müssen.
- Das erwartete Ausgabeformat
- Was zu vermeiden ist
Das Entwicklungsteam von Chudovo pflegt eine Bibliothek mit Codebeispielen für häufige Aufgaben: API-Client-Generierung, Migrationsskripte und Testumgebungen. Neue Teammitglieder nutzen diese sofort.
Tests sind ebenfalls obligatorisch. KI-generierter Code muss genauso getestet werden wie alles andere. Sie können die Testmuster des Projekts in Ihre Codebeispiele integrieren und die KI die Testfälle schreiben lassen. Wenn etwas fehlschlägt oder unklar ist, markieren Sie es zur genaueren Überprüfung.
Schließlich ist es wichtig zu wissen, wo KI nicht eingesetzt werden sollte. Kryptografische Implementierungen, Authentifizierungsabläufe und alles, was personenbezogene Daten (PII) oder Finanztransaktionslogik verarbeitet, sind Beispiele für Code, der manuell geschrieben werden sollte. Die Fehlerkosten sind zu hoch. Ein häufiges Muster in Unternehmensteams besteht darin, KI-generierte Standardvorlagen für interne Tools zuzulassen, während für Authentifizierungs-, Zahlungs- und Kundendaten-Workflows eine manuelle Implementierung und Überprüfung erforderlich ist.
Sicherheit, Compliance und sichere KI-gestützte Entwicklung
Die meisten cloudbasierten KI-Codierungstools senden Code an externe APIs. Wenn Ihre Codebasis Geschäftsgeheimnisse, Kundendaten oder andere Daten enthält, die Ihre Infrastruktur nicht verlassen dürfen, ist dies relevant. Lesen Sie die Datennutzungsbedingungen Ihres Anbieters. Viele Enterprise-Tarife beinhalten Verpflichtungen zur Datenspeicherung oder Opt-out-Optionen für Trainingsdaten. Diese müssen jedoch schriftlich bestätigt werden und dürfen nicht einfach auf Marketingseiten angenommen werden.
Selbstgehostete Modelle (Ollama, vLLM, private Bereitstellungen von Open-Weight-Modellen) sind eine praktikable Alternative für Teams, bei denen der Datenabfluss eine strikte Einschränkung darstellt. Der Funktionsunterschied zu cloudbasierten Modellen hat sich deutlich verringert.
SOC-2-, HIPAA- und ISO-27001-Audits fragen zunehmend nach der Nutzung von KI-Tools. KI-Tools gehören in Ihr Anbieterregister. Sie sollten nicht als Schatten-IT ohne entsprechende Richtlinienabdeckung agieren.
Sichere KI-gestützte Entwicklung beginnt mit dem Verständnis, wo Quellcode und Eingabeaufforderungen verarbeitet werden.
KI in SDLC-Prozessen
KI ist nicht nur in der Codierungsphase nützlich.
- Planung: Modelle können Epics zerlegen, technische Spezifikationen aus Anforderungen erstellen oder fehlende Grenzfälle in Akzeptanzkriterien aufdecken. Nur wenige Teams nutzen dies konsequent.
- Code-Review: Review-Tools können Logikfehler erkennen, Vereinfachungen vorschlagen und verdächtige Sicherheitsmuster kennzeichnen, bevor ein menschlicher Prüfer die Änderungen öffnet. Sie reduzieren die kognitive Belastung, ersetzen aber nicht den Menschen.
- Qualitätssicherung und Testen: KI hat sich als ausreichend erwiesen, um Grenzfallszenarien zu erstellen, Testpläne aus Spezifikationen zu generieren und Abdeckungslücken in bestehenden Testsuiten zu finden.
- Dokumentation: KI kann Änderungsprotokolle generieren, API-Dokumentationen aktualisieren und Abweichungen der Dokumentation von der Implementierung erkennen.
- Wartung: Bei der Übernahme einer bestehenden Codebasis kann KI die Funktion des Codes erklären, Refactoring-Pfade vorschlagen und bei der Erstellung von Regressionstests helfen, bevor Änderungen vorgenommen werden.
Fazit
Teams, die KI-gestützte Softwareentwicklungstools optimal nutzen, behandeln deren Ergebnisse wie einen ersten Entwurf eines zwar fähigen, aber fehleranfälligen Mitarbeiters. Sie überprüfen und testen ihn und legen dieselben Maßstäbe an wie von Menschen geschriebenen Code.
Ingenieure, die sich mit diesen Tools am schnellsten verbessern, verfügen bereits über ein solides Fundament. KI steigert die Produktivität, gleicht aber keine Beurteilungslücken aus. Wenn das Modell fehlerhaft ist (und das kommt regelmäßig vor), müssen die Ingenieure dies erkennen.
Nutzen Sie KI, um schneller voranzukommen. Nutzen Sie Ihre Ingenieurskompetenz, um fehlerfreie Ergebnisse zu erzielen. Beides ist untrennbar miteinander verbunden.
Надіслати відгук