Wenn Vibe Coding auf die Produktion trifft: Best Practices für Cleanup und Stabilisierung
Wenn wir „Vibe Coding“ in wenigen Worten beschreiben müssten, könnten wir sagen, dass es darin besteht, die gewünschten Funktionen in einfacher, natürlicher Sprache zu beschreiben und eine KI den Code basierend auf dieser Beschreibung generieren zu lassen. Im Gegensatz zur traditionellen Entwicklung muss man also keinen einzigen Codeabschnitt selbst schreiben. Theoretisch können Entwickler so beträchtliche Mengen an Code generieren, ohne jede Zeile manuell verfassen zu müssen. Die zugrundeliegende Sprache ist weiterhin wichtig (das Lesen, Überprüfen und Anpassen der KI-Ausgabe erfordert ein ausreichendes Verständnis, um Fehler des Modells zu erkennen), aber der Implementierungsaufwand verlagert sich deutlich.
Verschiedene Tools wie Cursor, GitHub Copilot und Claude haben dies für eine breite Palette von Entwicklern praktikabel gemacht. Ein funktionierender Prototyp innerhalb weniger Stunden ist keine Seltenheit. Der lästige Boilerplate-Code entfällt weitgehend. Diese Geschwindigkeit ist zwar beeindruckend, doch die Kosten, die später sichtbar werden, sind es auch.
Anwendungen, die auf diese Weise erstellt wurden, bestehen ihre erste Demo oft problemlos. Der Normalfall funktioniert, und auch eine kleine Anzahl von Benutzern bereitet keine Probleme.
Doch sobald der tatsächliche Datenverkehr steigt, sich die ursprünglichen Anforderungen ändern oder weitere Entwickler für neue Funktionen hinzugezogen werden, treten Probleme auf. Dann wird einem bewusst, welche Aspekte die Vibe-Code-Anwendung während der Entwicklung vernachlässigt hat. Die Codegenerierung selbst ist der einfache Teil. Die größere Herausforderung besteht darin, den generierten Code so aufzubereiten, dass er von einem Team bedient, erweitert und als zuverlässig angesehen werden kann.
Dieser Artikel untersucht die technischen Fehlerquellen und die notwendigen Aufräumarbeiten beim Vibe-Coding-Cleanup. Er erhebt keinen Anspruch auf Vollständigkeit, behandelt aber die häufigsten Fallstricke, in die Entwicklerteams (und manchmal auch nicht IT-Experten) bei der Vibe-Code-Entwicklung geraten sind.
Die technische Realität
Moderne Coding-Agenten verfügen über echte Mechanismen, um den Kontext über eine gesamte Codebasis hinweg aufrechtzuerhalten. Zu den beliebtesten Werkzeugen, die diesem Zweck dienen, gehören unter anderem:
- Cursor Rules
- AGENTS.md-Dateien
- Semantische Suche
- Repository-Indexierung
- MCP-basierte Integrationen
All diese Ansätze helfen. Die Lücke entsteht, wenn Teams diese Einrichtung überspringen.
Ein Projekt, in dem niemand das Kontextmanagement bewusst konfiguriert hat, wird sich so verhalten, als würde jede Sitzung bei null beginnen – nicht, weil die Werkzeuge es nicht besser könnten, sondern weil niemand sie dazu angewiesen hat. Ohne ausreichenden Kontext generiert das Modell das, was für die unmittelbare Aufgabe plausibel erscheint, während es möglicherweise Architekturentscheidungen, Geschäftsregeln oder Implementierungsdetails übersieht, die an anderer Stelle in der Codebasis existieren.
Das Ergebnis lässt sich leicht vorstellen: ein Stück Code, das auf Dateiebene korrekt aussieht, als Gesamtsystem jedoch nicht zusammenhält.
Wie bereits erwähnt, kann ein bewusstes Kontextmanagement durch den Entwickler helfen, dieses Risiko zu verringern. Doch das ist nicht das einzige Risiko, das berücksichtigt werden sollte. Nachfolgend finden Sie einige der wichtigsten Herausforderungen, die das Team von Chudovo nach der direkten Arbeit innerhalb eines Vibe-Coding-Workflows identifiziert hat:
Inkonsistente Architektur
Einer der häufigsten Ansätze beim Vibe Coding besteht darin, verschiedene Teile einer Anwendung in separaten Sitzungen mit leicht unterschiedlichen Prompts zu generieren. Für den Vibe Coder mag das gut aussehen, doch es führt zu Inkonsistenzen innerhalb der Codebasis: Ein Modul ruft Daten direkt aus der Datenbank ab, ein anderes verwendet eine Service-Schicht, und ein drittes greift auf einen REST-Endpunkt zu, der beide umgeht. Jede dieser Entscheidungen mag für sich genommen vertretbar sein. Wenn jedoch drei unterschiedliche Muster innerhalb derselben Codebasis nebeneinander existieren, wird jede zukünftige Änderung schwieriger, als sie sein müsste.
Das Cleanup beginnt damit, zu erfassen, was tatsächlich existiert – nicht das, was ursprünglich beabsichtigt war. Dokumentieren Sie die Datenflüsse, legen Sie einen Ansatz als Standard fest und migrieren Sie die Ausreißer.
Duplizierte Geschäftslogik
Eine weitere häufige Falle entsteht, wenn Geschäftsregeln an mehreren Stellen implementiert werden: in einem Controller, einem Hintergrundprozess, einer Frontend-Validierungsfunktion oder einem Datenbank-Trigger. Jede Kopie ist zum Zeitpunkt ihrer Erstellung korrekt. Mit der Zeit entwickeln sie sich jedoch stillschweigend auseinander.
Während der Stabilisierung eines Vibe-Coding-Projekts stellten die Ingenieure von Chudovo fest, dass die Rabattlogik im Checkout-Service ein anderes Ergebnis lieferte als die Bestellübersichtsseite. Die Ursachenanalyse beschäftigte zwei Ingenieure fast einen halben Nachmittag lang. Und das war nicht optional: Bevor man konsolidieren kann, muss man verstehen, was jede einzelne Version ursprünglich leisten sollte.
Versteckte technische Schulden
KI-generierter Code folgt dem Weg des geringsten Widerstands. Dieser Weg bringt jedoch häufig Probleme mit sich, die erst unter Last sichtbar werden. N+1-Abfragen sind das bekannteste Beispiel. Genau dieses Muster wurde während der Überprüfung eines KI-generierten E-Commerce-Backends identifiziert:
orders = Order.objects.all()
for order in orders:
# in the real code, this line was a separate DB query per iteration
print(order.customer.name) Bei zehn Bestellungen gibt es kein sichtbares Problem. Wenn die Anzahl auf zehntausend steigt, wird die Datenbank überlastet. Ein einzelner select_related-Aufruf behebt das Problem – allerdings nur, wenn es zuvor jemand entdeckt.
Weitere Muster, die häufig unbemerkt bleiben: Fehlerbehandlungen, die Ausnahmen ohne Protokollierung verschlucken, Connection Pools, die für einen Laptop statt für eine Produktionsumgebung dimensioniert sind, oder ausführliche Log-Ausgaben, die niemand auswertet.
Fehlende Testabdeckung
Tests erscheinen in KI-generiertem Code nur dann, wenn man ausdrücklich danach fragt. Wenn man nicht danach fragt, werden sie nicht erstellt. Die Tests, die dennoch geschrieben werden, bleiben meist an der Oberfläche: Gibt die Funktion einen Wert zurück? Wird eine Ausnahme ausgelöst? Randfälle und Fehlerszenarien werden häufig ausgelassen. Das Zusammenspiel mehrerer Komponenten wird kaum getestet.
Das Ergebnis ist eine Testsuite, die ein falsches Gefühl von Sicherheit vermittelt. Eine grüne CI-Pipeline ist nicht dasselbe wie eine korrekte Anwendung.
Sicherheitsrisiken
Sicherheitsprobleme in KI-generiertem Code sind meist von der offensichtlichen Art: Eingabevalidierungen, die nur auf der Client-Seite ausgeführt werden, SQL-Abfragen, die per String-Formatierung zusammengesetzt werden, oder API-Schlüssel, die direkt im Quellcode hinterlegt sind. Nichts davon ist besonders subtil. Es wird lediglich leicht übersehen, wenn das Ziel darin besteht, möglichst schnell einen funktionierenden Prototypen zu erstellen.
Das folgende SQL-Injection-Risiko ist häufig in KI-generiertem Code zu finden:
query = f"SELECT * FROM users WHERE email = '{email}'"Eine sicherere Variante würde wie folgt aussehen:
cursor.execute(
"SELECT * FROM users WHERE email = %s",
(email,)
)Die folgende Tabelle beschreibt die häufigsten Risiken von KI-generiertem Code:
| Risiko | Häufiges Muster in KI-generiertem Code | Korrekter Ansatz |
| SQL-Injektion | Per String-Formatierung zusammengesetzte Abfragen mit ungeprüften Eingaben | Parametrisierte Abfragen |
| Exposure von Secrets | Fest im Code hinterlegte API-Schlüssel oder in Git eingecheckte .env-Dateien | Speicherung und Rotation von Geheimnissen über einen dedizierten Secret Manager |
| Fehlende Authentifizierung | Endpunkte ohne Middleware zum Zugriffsschutz | Authentifizierungs-Middleware für alle geschützten Routen |
| Eingabevalidierung | Ausschließlich clientseitige Prüfungen | Serverseitige Validierung, unabhängig vom Client |
Skalierungsengpässe
N+1-Abfragen sind das sichtbarste Problem, aber bei weitem nicht das einzige:
- Synchrone Vorgänge, die im Hintergrund ausgeführt werden sollten, um Request-Threads nicht zu blockieren,
- Fehlende Indizes für Spalten, die ständig abgefragt werden, und
- Request-Handler, die immer mehr Logik ansammeln und unter hoher Parallelität langsamer werden.
All dies sind Beispiele für Anti-Patterns, die in KI-generiertem Code auftreten können. Im Demo-Maßstab fällt davon kaum etwas auf. Im Produktivbetrieb summieren sich diese Probleme jedoch und verstärken sich gegenseitig.
CI/CD- und Deployment-Lücken
Die Deployment-Konfiguration wird oft als Letztes erstellt und verursacht als Erstes Probleme. Staging- und Produktionskonfigurationen unterscheiden sich auf eine Weise, die nie dokumentiert oder nachverfolgt wurde. Health Checks liefern den Statuscode 200 zurück, unabhängig davon, ob die Anwendung tatsächlich eine Verbindung zur Datenbank herstellen kann. Ein Container, der auf einem Laptop problemlos läuft, kann in einem Kubernetes-Cluster stillschweigend scheitern, wenn die Readiness-Probe lediglich einen Endpunkt prüft, hinter dem keine echte Abhängigkeitsvalidierung stattfindet.
Wie Cleanup in der Praxis aussieht
Das Team von Chudovo folgt im Rahmen des Entwicklungsprozesses in der Regel einem praxisorientierten Ansatz:
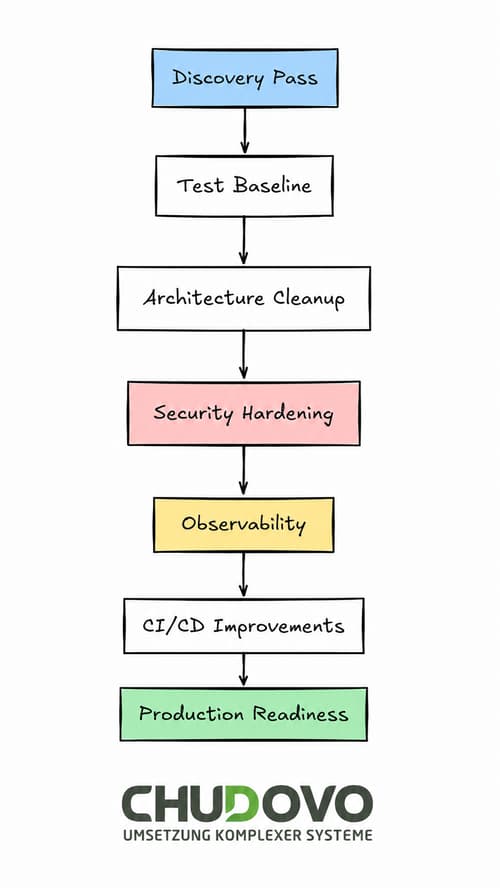
Die Discovery-Phase ist der erste Schritt, der vor jeglichen Änderungen durchgeführt werden sollte. Ihr Hauptzweck ist es, den bestehenden Zustand zu verstehen. Dazu müssen Entwickler den Code lesen, die Datenflüsse nachvollziehen und die Anwendung mit realen Nutzungsdaten testen. Wichtig ist dabei, alle Erkenntnisse zu dokumentieren, um die gravierendsten Probleme zu identifizieren und zu priorisieren. Nach der ersten Untersuchung und vor Beginn der Code-Refaktorisierung empfiehlt es sich, eine Testbasislinie zu erstellen. Selbst eine einfache Testschicht, die den Kernnutzerfluss abdeckt, kann hilfreich sein, da sie eine Grundlage für das Aufspüren potenzieller Regressionen bietet. Sie deckt außerdem Codeabschnitte auf, die sich Tests widersetzen, und zeigt strukturelle Probleme auf.
Im nächsten Schritt werden die Architektur priorisiert und bereinigt. Dazu muss ein Datenzugriffsmuster ausgewählt und redundante Geschäftslogik konsolidiert werden. Dies sollte schrittweise erfolgen, beginnend mit den aktuellsten Schwachstellen oder den Bereichen, die vom Team am häufigsten bearbeitet werden. Sobald die Architektur steht, muss die Sicherheit gewährleistet werden. Zu den klassischen Lösungsansätzen gehören die Parametrisierung von Abfragen, die Auslagerung von Geheimnissen in einen Geheimnismanager und das Hinzufügen von Authentifizierungs-Middleware. Ein Abhängigkeitsaudit ist ebenfalls unerlässlich, um potenzielle Probleme in Drittanbieterpaketen zu identifizieren und zu beheben. Dies muss erfolgen, bevor die Anwendung echte Benutzerdaten verarbeitet. Nicht gepatchte Abhängigkeiten sind ein häufiger Einfallstor für Angriffe, und ein Abhängigkeitsaudit ist der schnellste Weg, diese zu finden.
Die beiden letzten Schritte betreffen die Beobachtbarkeit und die CI/CD-Pipeline. Bezüglich der Beobachtbarkeit ist eine strukturierte Protokollierung mit Fehlerratenmetriken und Latenzwarnungen erforderlich. Dies ist entscheidend, denn ohne Einblick in die Vorgänge der Anwendung ist es schwierig, die Situation zu analysieren. Auf der Pipeline-Seite muss eine echte CI-Umgebung mit echten Tests implementiert werden. Verwenden Sie explizite Staging- und Produktionskonfigurationen sowie Integritätsprüfungen, die die tatsächlichen Abhängigkeiten und nicht nur die Prozessverfügbarkeit überprüfen.
Der vorgeschlagene Ansatz erhebt keinen Anspruch auf Vollständigkeit, aber die Reihenfolge ist wichtig: Zuerst analysieren, dann implementieren und beheben. Abschließend sollten Sie sich auf Continuous Delivery (CD) und Monitoring konzentrieren.
Wie lange dauert die Stabilisierung einer Vibe-Coded Codebasis?
Die Stabilisierung einer mit Vibe-Code entwickelten Codebasis dauert für einen kleinen Prototyp selten weniger als einige Wochen. Bei größeren Projekten rechnet man realistischerweise mit ein bis drei Monaten Teilzeit-Entwicklungsaufwand neben der regulären Feature-Entwicklung.
Der häufigste Fehler vieler Entwicklungsteams ist die Behandlung als Sprint: Man plant eine zweiwöchige Bereinigung, erklärt sie für abgeschlossen und macht weiter. In der Regel führt jede gefundene Fehlerbehebung zu neuen Problemen. Mehrere Sicherheitslücken treten während der Architekturprüfung auf; fehlende Indizes werden erst sichtbar, nachdem die Testbaseline langsame Abfragen aufdeckt. Mit der Zeit häufen sich die Probleme, und der ursprüngliche Plan gerät ins Wanken.
Ein guter Ansatz ist es, dies von Anfang an als iterativen Prozess zu betrachten. So erhält das Team ein Gefühl von stetigem (aber realem) Fortschritt und die Flexibilität, neue Aufgaben im Laufe des Prozesses zu integrieren. Die Frage, wann man aufhören sollte, ist ein anderes Thema. Die meisten Teams gehen davon aus, dass eine „produktionsreife“ Codebasis vollständig bereinigt ist. Durch ein solches Ziel iterieren die Teams immer wieder und verschieben den Release-Termin auf unbestimmte Zeit. Laut der Erfahrung des Chudovo-Teams ist eine Codebasis, die die folgenden vier Kriterien erfüllt, bereit – selbst wenn die Architektur stellenweise noch inkonsistent und die Testabdeckung noch lange nicht vollständig ist:
- Die Fehlermöglichkeiten sind dem Team bekannt
- Die kritischen Pfade sind getestet
- Die offensichtlichen Sicherheitslücken sind geschlossen
- Das Team kann Änderungen vornehmen, ohne befürchten zu müssen, etwas anderes zu beschädigen
Wichtig: Perfektion anzustreben ist hier eine Falle. Ziel ist ein System, das das Team mit angemessener Sicherheit betreiben und weiterentwickeln kann, nicht eines, das die Code-Review eines erfahrenen Entwicklers mit Bravour bestehen würde. Die Anforderungen können schrittweise erhöht werden, sobald das unmittelbare Risiko unter Kontrolle ist.
Schritt für Schritt statt alles auf einmal
Auch wenn den meisten Entwicklungsteams die oben genannten Themen bewusst sind, besteht häufig die Versuchung, alles gleichzeitig zu beheben. Das Ergebnis ist oft ein Kreislauf ohne Ende: Der Umfang des Cleanups wächst ständig weiter, und die Produktionsfreigabe rückt immer weiter in die Ferne.
Wie in den vorherigen Abschnitten beschrieben, ist ein umfassendes Refactoring einer KI-generierten Codebasis ein großes und risikoreiches Vorhaben, das viele Möglichkeiten bietet, neue Probleme einzuführen. Teams, die solche Codebasen erfolgreich stabilisieren, gehen in der Regel schrittweise vor. Sie beheben den aktuellen Blocker, ergänzen Tests laufend und entwickeln die Architektur über Wochen hinweg in Richtung größerer Konsistenz weiter. Der Fortschritt fühlt sich dadurch langsamer an, aber die Anwendung bleibt währenddessen funktionsfähig.
KI kann die Softwareentwicklung erheblich beschleunigen. Die Zuverlässigkeit im Produktivbetrieb hängt jedoch weiterhin von Architektur, Tests, Observability und operativer Disziplin ab. Erfolgreich sind nicht die Teams, die den meisten Code generieren. Erfolgreich sind die Teams, die solchen Code als Ausgangspunkt betrachten – und nicht als fertiges Produkt.