Datenbankmigration ohne Ausfallzeiten für Legacy-Systeme Ein praktischer Entwicklerleitfaden
Bei der Migration von Datenbanken ohne Ausfallzeiten treffen gute Absichten auf die Realität im Produktivbetrieb. Nach jahrelangen Änderungen im Produktivbetrieb häufen sich die Herausforderungen bei der Datenbankmigration schnell.
Legacy-Systeme bringen eine weitere Ebene mit sich:
- Jahrelange undokumentierte Änderungen
- Fremdschlüsselbeziehungen, die nirgendwo im Quellcode existieren
- Datenmengen, die Tests in der Entwicklungsumgebung weitgehend sinnlos machen.
In fast allen Fällen gibt es kein Wartungsfenster. Das System muss verfügbar bleiben.
Ob Sie sich in dieser Situation befinden (oder ihr lieber entgehen möchten), ist dieser Leitfaden für Sie. Hier stellen wir Ihnen verschiedene Techniken vor, die sich in realen Produktionsumgebungen bei der Datenbankmigration bewährt haben. Kompromisse werden explizit benannt, und die Schritte sind so detailliert beschrieben, dass sie leicht nachvollziehbar sind.
Warum Ausfallzeiten wichtiger sind, als Sie denken
Jedes Mal, wenn eine Datenbank offline genommen wird, hat das weitreichende Auswirkungen, die oft nicht sofort sichtbar sind. Abhängige Dienste können Zeitüberschreitungen verursachen, Hintergrundprozesse schlagen möglicherweise unbemerkt fehl oder sammeln sich in Warteschlangen an, bis die Datenbank wieder verfügbar ist – und belasten sie anschließend mit einer Flut von Wiederholungsversuchen.
Diese Effekte können selbst bei einer nur kurzen Unterbrechung auftreten. Die tatsächlichen Folgen hängen jedoch stark von der jeweiligen Architektur ab. Systeme, die vollständig als Monolith aufgebaut sind, können ein 30-minütiges Migrationsfenster unter Umständen verkraften. In verteilten Systemen hingegen können dieselben 30 Minuten eine Kettenreaktion von Fehlern in Diensten auslösen, die an der eigentlichen Migration gar nicht beteiligt sind. Besonders kritisch ist dies in regulierten Branchen wie dem Finanzwesen oder dem Gesundheitssektor. Dort kann bereits eine ungeplante Ausfallzeit Meldepflichten und Incident-Reports nach sich ziehen – unabhängig davon, ob die Nutzer die Auswirkungen überhaupt bemerkt haben.
In der Praxis bedeutet „Zero Downtime“ daher nicht, dass es keinerlei Auswirkungen gibt. Vielmehr geht es darum, die Beeinträchtigungen so gering zu halten, dass sie für das System und die Anwender praktisch unsichtbar bleiben. Es handelt sich dabei um ein Ziel, das angestrebt wird, und nicht um eine absolute Garantie.
Die zentrale Herausforderung bei Datenbankmigrationen ohne Ausfallzeiten: Datenkonsistenz während der Migration
Das Hauptproblem bei einer Live-Datenbankmigration besteht darin, dass die Anwendung weiterhin Daten liest und schreibt, während sich das Datenbankschema verändert. Wenn beispielsweise eine neue Spalte hinzugefügt und gleichzeitig neuer Anwendungscode bereitgestellt wird, entsteht eine kritische Übergangsphase. Der alte Code schreibt Datensätze noch ohne die neue Spalte, während der neue Code diese bereits voraussetzt. Das kann zu Fehlern in der Datenbank führen – oder, noch problematischer, dazu, dass unbemerkt Nullwerte gespeichert werden.
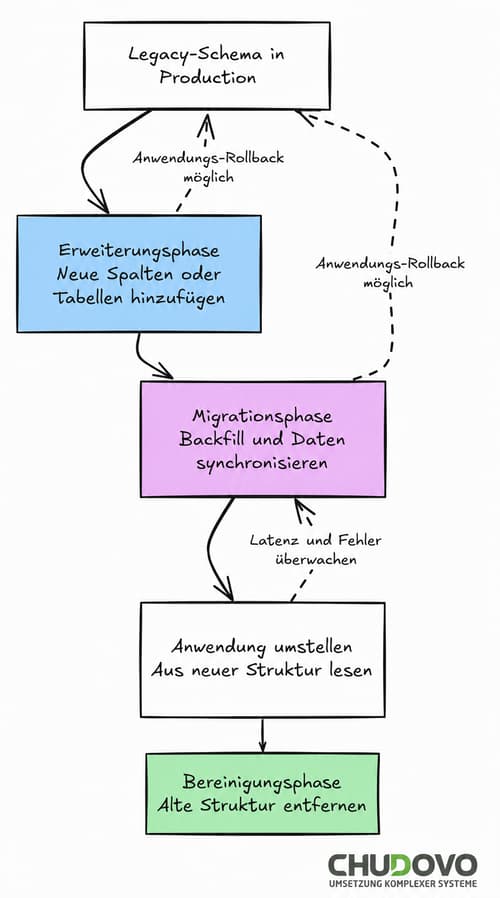
Eine bewährte Methode zur Lösung dieses Problems ist das Expand-Contract-Muster (auch als Parallel Change Pattern bekannt). Die meisten sicheren Ansätze für Schemaänderungen ohne Ausfallzeiten basieren auf diesem Prinzip oder einer Variante davon.
Das Muster besteht aus drei Phasen. Zunächst erfolgt die Erweiterungsphase (Expand Phase). Dabei wird die neue Datenstruktur eingeführt, während die bestehende Struktur unverändert erhalten bleibt. Neue Spalten oder Tabellen werden angelegt, jedoch noch nicht von der Anwendung genutzt.
Anschließend folgt die Migrationsphase (Migrate Phase). In dieser Phase werden die Daten im Hintergrund übertragen oder transformiert, während die Anwendung weiterhin mit der bisherigen Struktur arbeitet. Für die Nutzer bleibt der Betrieb dabei unverändert bestehen.
Den Abschluss bildet die Bereinigungsphase (Contract Phase). Erst nachdem sämtliche Daten erfolgreich migriert wurden und die Anwendung vollständig auf die neue Struktur umgestellt ist, werden die alten Tabellen, Spalten oder andere veraltete Elemente entfernt. Dieser Schritt erfolgt in der Regel als separates Release, um Risiken weiter zu minimieren.
Sollte während der Erweiterungs- oder Migrationsphase ein Problem auftreten, kann der Anwendungscode zurückgesetzt werden. Da die ursprüngliche Datenbankstruktur weiterhin vorhanden ist, sind in diesem Fall keine zusätzlichen Änderungen am Schema erforderlich. Dies macht das Expand-Contract-Muster zu einer der sichersten Strategien für Datenbankmigrationen ohne Ausfallzeiten.
Migrationsmuster, die in der Praxis funktionieren
Expand-Contract-Muster (Parallel Change)
Wie bereits erläutert, ist dies wahrscheinlich das zuverlässigste Verfahren für Datenbankmigrationen ohne Ausfallzeiten. Tatsächlich setzen die meisten Entwicklungsteams bei produktiven Systemen auf solche Techniken für Schemaänderungen ohne Unterbrechung. Die Phase, in der sowohl die alte als auch die neue Struktur parallel existieren, kann sich über mehrere Deployments erstrecken. Das ist völlig normal, bringt jedoch einen gewissen Mehraufwand mit sich: Alte und neue Strukturen müssen gleichzeitig betrieben werden – manchmal über mehrere Wochen hinweg. Dieser zusätzliche Aufwand ist jedoch beherrschbar. Unerwartete Ausfälle hingegen sind es nicht.
Betrachten wir ein Beispiel: Sie möchten die Spalte user_name in display_name umbenennen. Zunächst wird die neue Spalte display_name hinzugefügt. Ab diesem Zeitpunkt schreibt die Anwendung Daten in beide Spalten. Anschließend werden alle bestehenden Datensätze vollständig in die neue Spalte übertragen. Erst danach werden die Lesevorgänge auf display_name umgestellt. In einem separaten Release werden schließlich die Schreibvorgänge für user_name beendet und die alte Spalte entfernt.
Blue-Green-Deployment als Datenbankstrategie
Eine weitere verbreitete Strategie für Datenmigrationen in Legacy-Systemen ist das sogenannte Blue-Green-Deployment. Vereinfacht gesagt werden dabei zwei Umgebungen parallel betrieben, und der Datenverkehr wird über den Load Balancer zwischen ihnen umgeschaltet. Für Datenbanken gilt dasselbe Prinzip: Es existieren zwei Instanzen – eine aktive und eine zweite, die für die Migration vorbereitet wird.
Die größte Herausforderung besteht darin, die Daten zwischen beiden Instanzen zu synchronisieren. Während der Übergangsphase müssen Schreibvorgänge entweder auf beide Datenbanken verteilt werden oder es wird eine kurze, kontrollierte Pause auf Anwendungsebene eingelegt. Im Gegensatz zu einem vollständigen Ausfall ist diese Unterbrechung jedoch geplant, dauert meist nur wenige Sekunden und kann problemlos rückgängig gemacht werden.
Blue-Green-Deployments eignen sich besonders für größere Versionsupdates oder tiefgreifende strukturelle Änderungen, die sich nicht schrittweise umsetzen lassen. Ein weiterer Vorteil: Ein Rollback ist einfach möglich, indem der Datenverkehr wieder auf die ursprüngliche Umgebung umgeleitet wird.
Canary Releases für Datenbankänderungen
Bei diesem Ansatz wird zunächst nur ein kleiner Teil des Datenverkehrs – beispielsweise fünf Prozent – auf das neue Datenbankschema geleitet. Bleiben Fehlerraten und Antwortzeiten stabil, wird die Umstellung schrittweise auf weitere Nutzer ausgeweitet. Treten Probleme auf, kann die Änderung zurückgenommen werden, ohne dass die Mehrheit der Anwender betroffen ist.
Die wichtigste technische Voraussetzung hierfür ist das sogenannte Dual Writing. Während der Canary-Phase schreibt die Anwendung gleichzeitig in das alte und das neue Schema. Diese Logik wird auf Anwendungsebene umgesetzt. Zwar erhöht dies die Komplexität der Anwendung, sorgt jedoch dafür, dass die Daten während der schrittweisen Einführung in beiden Schemata konsistent bleiben. Dadurch kann die Migration kontrolliert und mit minimalem Risiko durchgeführt werden.
KI-gestützte Modernisierung für die Migration von Legacy-Datenbanken
Der Einsatz von KI-gestützten Werkzeugen trägt zunehmend dazu bei, den operativen Aufwand bei Migrationsprojekten für Legacy-Datenbanken zu reduzieren. Mit solchen Tools können Teams wiederkehrende Analyseaufgaben beschleunigen, die traditionell eine aufwendige manuelle Prüfung erfordern. Dennoch ersetzen sie weder eine sorgfältige Migrationsplanung noch durchdachte Rollback-Strategien.
Werfen wir einen Blick auf einige der häufigsten Anwendungsfälle.
Einer der ersten Schritte jeder Datenbankmigration ist die Abhängigkeitsanalyse. Bevor bestehender Code entfernt oder verändert wird, muss klar sein, welche Teile des Systems davon betroffen sind. In älteren Systemen, die über viele Jahre gewachsen sind, existieren häufig umfangreiche Geschäftslogiken, Stored Procedures und Reporting-Prozesse, die von nicht dokumentierten Beziehungen innerhalb des Datenbankschemas abhängen. Eine manuelle Analyse dieser Abhängigkeiten kann schnell sehr komplex und zeitaufwendig werden.
KI-gestützte Werkzeuge können solche Zusammenhänge deutlich schneller erkennen, indem sie unter anderem folgende Informationen analysieren:
- Abfragemuster (Query Patterns)
- ORM-Mappings
- Log-Dateien
- Historische Datenbanknutzung
Auf dieser Grundlage erhalten Entwicklungsteams eine Übersicht über die vorhandenen Abhängigkeiten sowie die Änderungen, die bei der Migration berücksichtigt werden müssen.
Einige Unternehmen nutzen darüber hinaus KI-basierte Migrationsassistenten, um Migrationsskripte zu erstellen, potenziell problematische Schemaänderungen frühzeitig zu erkennen oder die Auswirkungen lang laufender Datenbankoperationen vor deren Ausführung abzuschätzen. Besonders bei groß angelegten Modernisierungsprojekten, bei denen mehrere Anwendungen oder Services auf dieselbe produktive Datenbank zugreifen, bieten solche Werkzeuge einen erheblichen Mehrwert.
Wie man sieht, unterstützen KI-Tools Entwickler dabei, Analyseaufgaben und wiederkehrende Tätigkeiten zu automatisieren, die sonst viel Zeit und manuelle Arbeit erfordern würden. Dadurch können sich Teams stärker auf die entscheidenden Aspekte eines Migrationsprojekts konzentrieren: Strategie, Planung und Umsetzung.
KI-gestützte Workflows können die Qualität von Migrationen verbessern und die Projektlaufzeit verkürzen. Die grundlegenden Prinzipien erfolgreicher Datenbankmigrationen bleiben jedoch unverändert. Sichere Migrationen in Produktivumgebungen erfordern weiterhin additive Schemaänderungen, schrittweise Rollouts, Tests unter produktionsnahen Bedingungen sowie einen klar definierten und validierten Rollback-Pfad.
Schritt-für-Schritt-Anleitung: So migrieren Sie eine Datenbank ohne Ausfallzeiten
So strukturiert das Team von Chudovo eine sichere Datenbankmigration in einer Produktivumgebung, wenn eine Legacy-Datenbank mit einer großen Tabelle migriert werden muss:
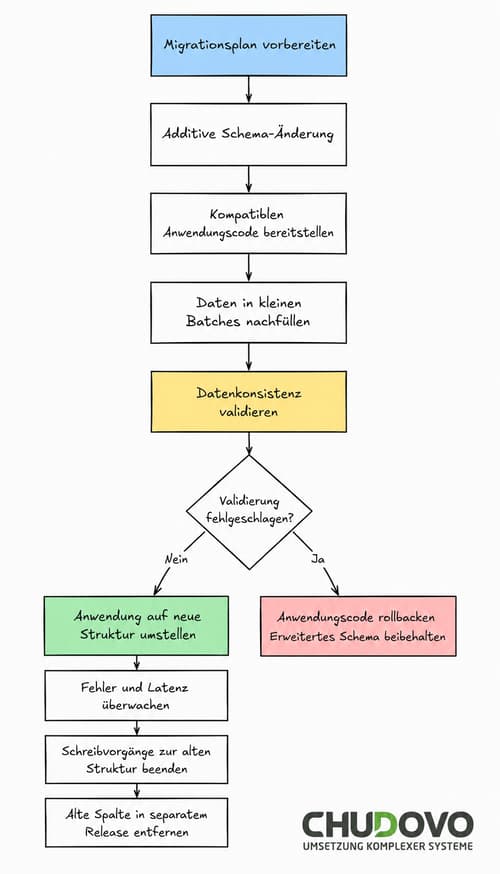
Die schrittweise Verarbeitung (Batching) des Backfills ist bei großen Tabellen keine Option, sondern eine Notwendigkeit. Ein einzelnes UPDATE über 50 Millionen Datensätze hält Zeilensperren (Row Locks) lange genug aufrecht, um spürbare Latenzspitzen im Produktivsystem zu verursachen. Durch die Verarbeitung in kleineren Chargen von etwa 1.000 bis 10.000 Datensätzen sowie kurze Pausen zwischen den einzelnen Durchläufen lässt sich die Belastung so gering halten, dass sie im laufenden Betrieb praktisch nicht wahrnehmbar ist.
Vergleich der Migrationsmuster
Nachfolgend finden Sie eine Übersicht der wichtigsten Migrationsmuster, die in den vorherigen Abschnitten vorgestellt wurden:
| Muster | Am besten geeignet für | Risikoniveau | Komplexität des Rollbacks |
| Expand-Contract | Umbenennung oder Erweiterung von Spalten und Tabellen | Niedrig | Niedrig |
| Blue-Green | Größere Versionsupgrades | Mittel | Mittel |
| Canary Release | Schemaänderungen bei sensiblem Datenverkehr | Mittel | Hoch |
| Online DDL | Indexerstellung und kleinere Schemaänderungen | Niedrig-Mittel | Niedrig |
Wir möchten die letzte Zeile näher betrachten. Online-DDL-Funktionen wurden mit MySQL 5.6 eingeführt und in MySQL 5.7 sowie 8.0 erheblich erweitert. PostgreSQL unterstützt nicht blockierende Operationen wie CREATE INDEX CONCURRENTLY, jedoch erfordern viele ALTER TABLE-Operationen weiterhin exklusive Sperren. Für Schemaänderungen mit nahezu keinen Ausfallzeiten können zusätzliche Tools erforderlich sein. Diese Operationen reduzieren oder vermeiden lang andauernde Sperren während Schemaänderungen. Allerdings eignen sich nicht alle DDL-Typen dafür, und das Verhalten variiert je nach Datenbank-Engine und Version.
Häufige Fehler, die man vermeiden sollte
Migrationen als Teil des Deployments
Es kann verlockend sein, die Migration als Bestandteil der Release-Pipeline auszuführen. In manchen Fällen funktioniert das auch. Ist die Migration jedoch zeitaufwendig, kann sie die gesamte Pipeline blockieren. Ein bewährter Ansatz besteht darin, Schema-Migrationen getrennt von Anwendungsdeployments durchzuführen.
Kein Rollback-Plan
Es gibt keine Garantie dafür, dass eine Migration erfolgreich verläuft. Tatsächlich treten Probleme häufig auf. Manche lassen sich beheben, in anderen Fällen ist jedoch ein Rollback auf den vorherigen Zustand erforderlich. Deshalb sollte jeder Migrationsplan einen klar definierten Rückweg enthalten. Bei Schemaänderungen sollten alte Spalten während der Übergangsphase weiterhin verfügbar bleiben. Bei Datentransformationen empfiehlt es sich, vor Beginn eine Sicherungskopie zu erstellen. Das erspart viel Aufwand, falls die Migration nicht wie geplant verläuft.
Falscher Datenumfang beim Testen
Testumgebungen bilden die Realität von Produktivsystemen oft nicht vollständig ab. Eine Migration, die bei 100.000 Datensätzen nur drei Sekunden benötigt, kann auf einer Produktivdatenbank mehrere Stunden dauern. Die Migration allein anhand der Ergebnisse aus Testumgebungen zu bewerten, ist ein häufiger Fehler. Tests sollten immer mit Datenmengen durchgeführt werden, die den tatsächlichen Produktionsbedingungen möglichst nahekommen.
Schema- und Datenmigration in einem Schritt
Schemaänderungen und Datenmigrationen weisen unterschiedliche Risikoprofile auf. Werden beide in einem einzigen Schritt durchgeführt, wird es schwieriger, Probleme zu isolieren und gegebenenfalls ein Rollback durchzuführen. Die Aufteilung in separate Phasen bietet mehr Kontrolle und reduziert das Gesamtrisiko der Migration.
Rollback-Strategien für die Planung von Datenbankmigrationen
Wie bereits erwähnt, verlaufen Migrationen nicht immer wie geplant. Deshalb gehört eine durchdachte Rollback-Strategie zu den wichtigsten Best Practices bei der Migration von Legacy-Datenbanken. Ihr Hauptziel besteht darin, festzulegen, wie sich das System erholen kann, wenn in der Produktionsumgebung unerwartete Probleme auftreten.
Ein Rollback kann aus drei Perspektiven betrachtet werden: Anwendung, Daten und Schema.
- Rollback der Anwendung: Dieser Ansatz hängt davon ab, ob die vorherige Version der Anwendung weiterhin mit dem neuen Datenbankschema arbeiten kann. Dank des Expand-Contract-Musters lässt sich die Datenbank durch additive Änderungen – beispielsweise das Hinzufügen neuer, optionaler Spalten – weiterentwickeln, während die Abwärtskompatibilität zwischen verschiedenen Anwendungsversionen erhalten bleibt. Da sowohl die alte als auch die neue Struktur weiterhin bestehen und durch kontrollierte Dual-Write-Mechanismen synchron gehalten werden, kann das System ohne Datenverlust oder Ausfallzeit sofort auf die vorherige Anwendungsversion zurückgesetzt werden.
- Rollback der Daten: Hier geht es um die Fähigkeit, sich von unerwarteter Datenbeschädigung oder Datenverlust zu erholen, die während einer Transformation auftreten können. Neben den üblichen Point-in-Time-Recovery-Verfahren (PITR) empfiehlt sich der Einsatz temporärer „Shadow Tables“, in denen die ursprünglichen Datensätze gespeichert werden, bevor sie transformiert werden. Dadurch lassen sich einzelne Datensätze gezielt wiederherstellen, ohne die gesamte Datenbank zurücksetzen zu müssen. Bei Cloud-Snapshots sollte zudem geprüft werden, ob das Restore Time Objective (RTO) mit den zulässigen Ausfallzeiten vereinbar ist, da die Wiederherstellung großer Datenmengen mehrere Stunden dauern kann. Wiederherstellungszeiten sollten insbesondere bei sehr großen Datenbanken im Vorfeld gemessen und validiert werden.
Bei sehr großen Tabellen erfordern Shadow-Table-Ansätze möglicherweise zusätzliche Planung hinsichtlich Speicherbedarf und Sperrmechanismen.
- Rollback des Schemas: Im Mittelpunkt steht hier die Rücknahme struktureller Änderungen an der Datenbank. Destruktive Aktionen wie das Löschen einer Tabelle oder das Umbenennen einer Spalte sind unmittelbar wirksam und oft nicht ohne Weiteres rückgängig zu machen. Deshalb sollten solche Änderungen erst durchgeführt werden, nachdem die Migration vollständig überprüft wurde. Zusätzlich sollte für jedes Migrationsskript ein entsprechendes „Revert Script“ erstellt und getestet werden, mit dem sich DDL-Änderungen – beispielsweise neu angelegte Indizes oder Constraints – schnell rückgängig machen lassen. Außerdem sollte stets überprüft werden, ob die Backup- und Wiederherstellungsprozesse in einer Staging-Umgebung tatsächlich funktionieren. Ein Backup, das nie getestet wurde, ist kein verlässlicher Rollback-Plan.
Je nach Anforderungen des jeweiligen Systems können unterschiedliche Ansätze sinnvoll sein. Die wichtigste Regel bleibt jedoch dieselbe: Testen Sie den Rollback-Plan vor der Migration und nicht erst dann, wenn bereits Probleme aufgetreten sind.